Claude Code × Codex デスクトップアプリ最大活用:コンテンツ無限生成の教科書
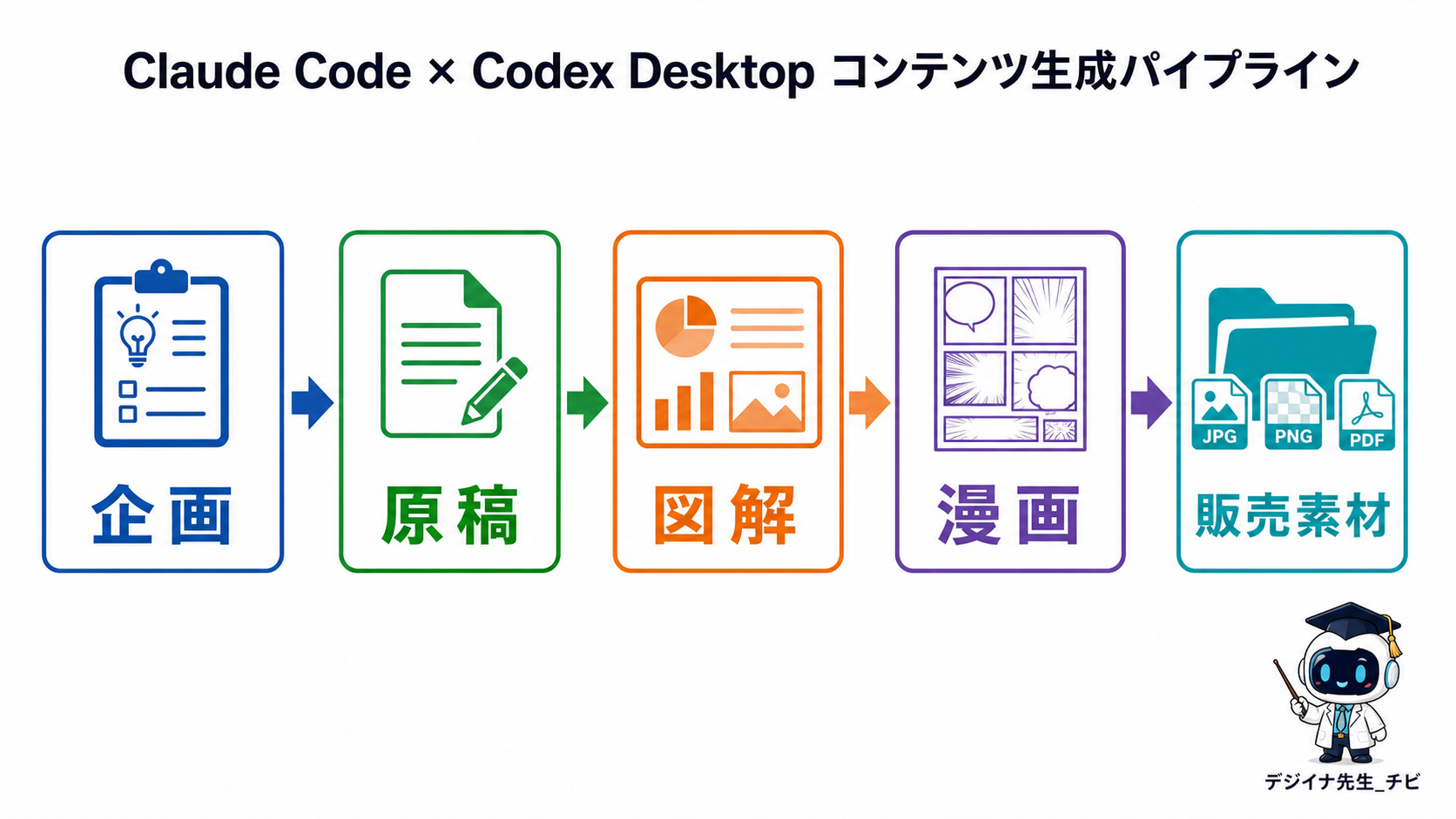
Claude Code × Codex Desktop コンテンツ生成パイプライン
はじめに
「AIを使えばコンテンツを無限に作れる」と聞くと、少しわくわくする一方で、どこか怪しく感じる人も多いはずです。
Kindle出版、ブログ、YouTube台本、SNS投稿、教材、漫画。
どれもAIで作れそうに見えますが、実際に始めてみると、最初の壁にぶつかります。
何を頼めばよいのか分からない。
生成された文章が本当に使えるのか判断できない。
保存場所が散らかる。
画像やDOCXを作る段階で止まる。
あとから直そうと思っていたら、どれが最新版か分からなくなる。
こうした悩みは、AIの性能だけで解決するものではありません。
本書のテーマは、Claude CodeとCodexデスクトップアプリを使って、初心者でも「作り続けられる仕組み」を作ることです。
Claude CodeはAnthropicが提供する、プロジェクト内のファイルを読みながら作業できるAI開発支援ツールです。
AnthropicはClaudeを開発している企業です。
CodexデスクトップアプリはOpenAIのCodexをローカル作業に使いやすくした環境で、会話しながらファイル作成や確認を進められます。
OpenAIはChatGPTやCodexを提供する企業です。
ここでいうコンテンツ無限生成とは、ボタンを押せば勝手に売れる本が無限にできる、という意味ではありません。
むしろ逆です。
毎回ゼロから悩まないために、企画、リサーチ、原稿、図解、漫画、DOCX化、販売素材までの流れを、再利用できる作業手順にしていく考え方です。
Claude Codeは、コードを書く人だけの道具だと思われがちです。
しかし、本質は「プロジェクトの中身を読み、ファイルを編集し、コマンドを実行し、検証しながら進めるエージェント型の作業環境」です。
エージェントとは、ただ返事をするだけでなく、目的を見て、必要な手順を選び、作業を進めるAIの担当者のことです。
これは文章制作にも向いています。
なぜなら、電子書籍制作もまた、たくさんのファイルと手順を扱うプロジェクトだからです。
Codexデスクトップアプリは、その作業を見ながら進める場所として使えます。
複数の作業を並行させたり、スキルを読み込ませたり、ローカルのファイルを実際に作ったりできます。
チャットで相談するだけで終わらず、成果物として `research.md`、`manuscript_raw.md`、`image_prompts.md`、`manga_pages.csv`、`final_book.docx` のようなファイルに落としていくのが、本書の中心です。
本書は、Amazon Kindleで副業やAIに興味を持ち始めた初心者に向けて書いています。
プログラミング経験が豊富でなくても読めるよう、抽象的な考え方から始め、少しずつ具体例へ進みます。
一方で、ただ夢を語るだけの本にはしません。
安全設計、バックアップ、公式スキルの確認、信頼できる配布元、漫画化しやすい原稿構造まで、実務でつまずきやすい部分も丁寧に扱います。
読み終えたときのゴールは、「AIで何か作れそう」ではありません。
「このテーマなら、こういうフォルダを作り、この順番で依頼し、この成果物を確認し、次の工程へ渡せばよい」と自分で判断できる状態です。
AIを魔法の箱として使うのではなく、仕事を分けて頼める制作チームとして扱えるようになること。
それが、本書で目指す変化です。

第1章: なぜ今 Claude Code × Codex なのか
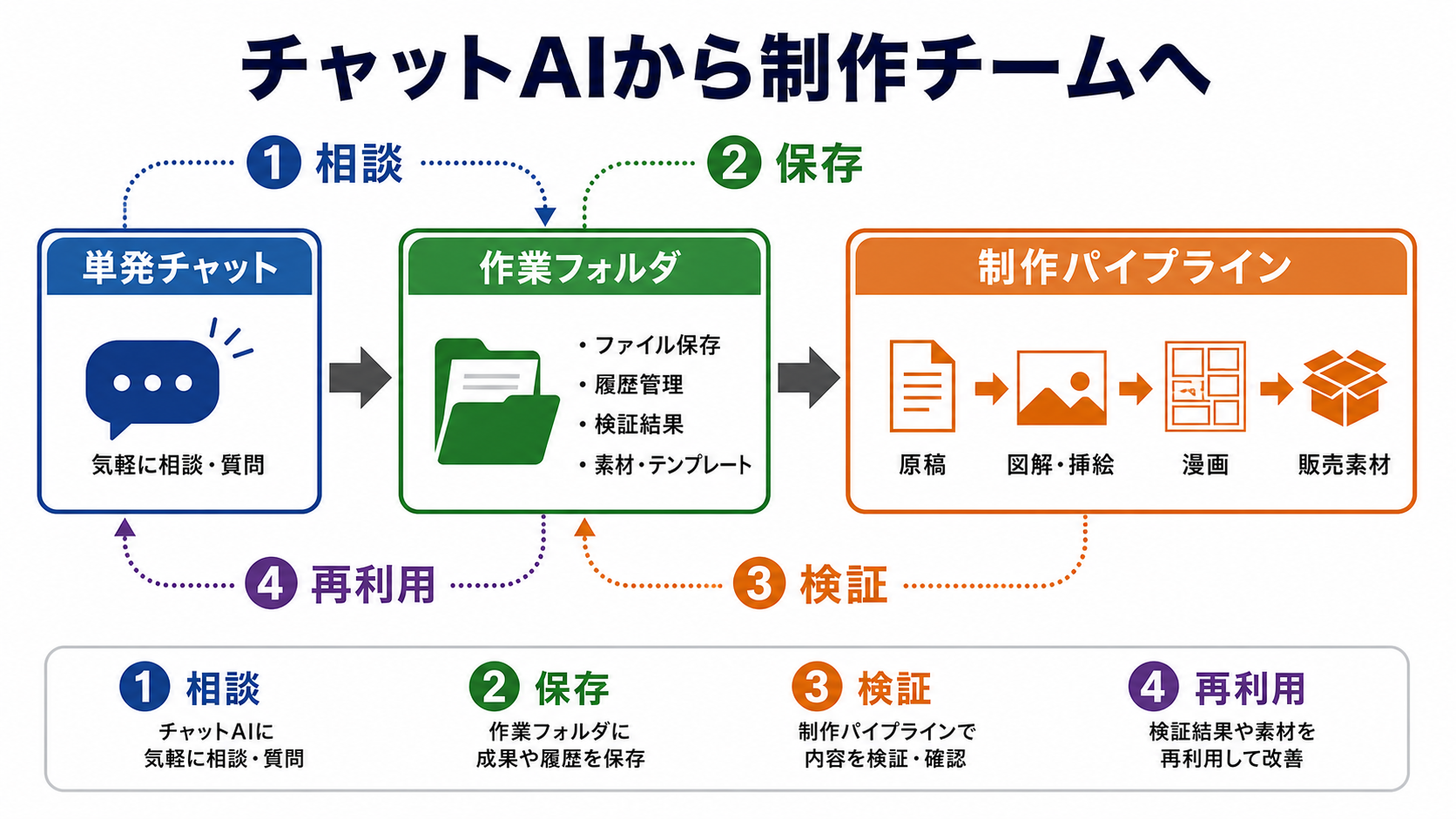
チャットAIから制作チームへ
AIツールの情報は、とても速く変わります。
昨日まで話題だったツールが、今日には別の名前に置き換わっていることもあります。
初心者にとって難しいのは、どのツールが一番強いかを判断することではありません。
自分の作業にどう組み込めばよいかを決めることです。
Kindle出版を例にすると、必要な作業は文章生成だけではありません。
テーマ選定、読者の悩みの整理、競合調査、章立て、本文執筆、図解の設計、漫画化、DOCX化、表紙や販売文の準備、誤字脱字チェック、ファイル管理があります。
ひとつひとつは小さく見えても、全部を一人で抱えるとすぐに混乱します。
ここでClaude CodeとCodexデスクトップアプリの組み合わせが役に立ちます。
Claude Codeは、ファイルを読みながら作業し、手順やルールをプロジェクトに残す考え方を教えてくれます。
Codexデスクトップアプリは、その考え方を実際の作業場として動かしやすい環境です。
どちらも、ただ質問に答えるだけのチャットとは違い、プロジェクト単位で仕事を進める発想を持っています。
初心者が最初に持つ悩みは、「AIに何を頼めばよいのか分からない」というものです。
たとえば「AI副業の本を書いて」と頼めば、何かしら文章は出ます。
しかし、その文章が読者の悩みに合っているか、図解にしやすいか、あとで漫画化できるか、Kindle用DOCXに変換しやすいかまでは分かりません。
単発のプロンプトだけでは、工程全体を見失いやすいのです。
大切なのは、AIに頼む作業を「成果物名」で分けることです。
最初の成果物は `research.md` です。
ここには、読者の悩み、競合の傾向、章ごとの材料をまとめます。
次の成果物は `manuscript_raw.md` です。
ここには本文と図解タグを入れます。
さらに `image_prompts.md`、`manuscript.md`、`manga_pages.csv`、`final_book.docx` と進みます。
成果物名が決まると、AIへの依頼も具体的になります。
Claude Codeが教えてくれる強みは、この「作業をファイルに分ける」発想です。
コード開発では、設計書、ソースコード、テスト、設定ファイル、ログを分けて扱います。
コンテンツ制作でも同じです。
企画、原稿、画像プロンプト、漫画シナリオ、DOCXを分けておけば、途中で問題が起きても戻れます。
逆に、チャット欄だけで全部を進めると、どこからやり直せばよいか分からなくなります。
Codexデスクトップアプリの良さは、こうしたファイル操作と会話が同じ作業環境にまとまることです。
作業中のフォルダを開き、指示ファイルを読み、必要なファイルを作り、コマンドを実行し、結果を確認できます。
メインの作業者がスキル構成を整え、別の作業者が原稿を作る、という分担も可能になります。
本書そのものも、その分担を前提にしています。
「コンテンツ無限生成」という言葉には、注意も必要です。
無限に作れるからといって、無限に価値が出るわけではありません。
読者の悩みがずれていれば、どれだけ量産しても読まれません。
事実確認が甘ければ、信用を失います。
似たような本文を量産すれば、販売ページで見抜かれます。
だからこそ、生成量より先に、制作ルールと検証ルールを決める必要があります。
たとえば、1冊の本を作るときに、次のように役割を分けます。
リサーチ担当は読者の悩みと材料を集める。
原稿担当は初心者が読める順番に並べる。
図解担当は文字の大きい図解タグを作る。
漫画担当は読者の悩み、気づき、実践ステップを場面に変換する。
レビュー担当は危ない断定や古い情報を確認する。
この役割分担ができると、AIは「何でも屋」ではなく、制作チームになります。
この考え方は、副業初心者にとって特に大事です。
副業では、時間も集中力も限られています。
毎回ゼロから考える方法では続きません。
仕事のあとに1時間だけ作業するなら、今日は `research.md`、明日は第1章、週末は図解タグ、というように工程を分ける必要があります。
Claude CodeとCodexは、その分割を支える道具です。
もうひとつの価値は、失敗を学習資産にできることです。
たとえば「図解の文字が小さすぎた」という失敗があれば、次回から画像タグに「主要ラベル3〜5個」「拡大しなくても読める文字」と書きます。
「漫画で吹き出しに話者名まで入ってしまった」なら、漫画スキルに「ふきだし内には本文だけ」と書きます。
失敗をプロンプトの反省で終わらせず、スキルやルールに移すことで、次の制作が楽になります。
さらに、ひとつのテーマから複数のコンテンツへ広げられる点も見逃せません。
たとえば本書のテーマなら、Kindle本の本文だけでなく、図解スライド、漫画ページ、無料プレゼント用PDF、SNS投稿、販売ページの説明文、メルマガの導入文まで展開できます。
ただし、最初から全部を作ろうとすると破綻します。
最初に作るべき中心素材は、読者の悩みと解決手順が整理された原稿です。
原稿がしっかりしていれば、図解も漫画も販売文も作りやすくなります。
この順番は、初心者の不安を減らすうえでも効果があります。
「いきなり商品を作る」と考えると重く感じますが、「今日は読者の悩みを整理する」「明日は章立てを作る」「週末に図解タグを入れる」と考えれば、作業は小さくなります。
Claude CodeとCodexを使う意味は、作業を大きく見せることではありません。
大きな制作を、小さな確認可能な工程に分けることです。
一方で、やらないことを決めるのも大切です。
本書では、著作権のある文章を長く取り込んで言い換えるだけの量産、根拠のない収益断定、読者を急かす過度な煽り、確認していない最新情報の断定は避けます。
AIで作れる量が増えるほど、信頼を失う速度も上がります。
だから、制作パイプラインの中に「事実確認」「表現確認」「読者に本当に役立つか」のチェックを入れます。
読者の悩みは、「AIを使えば楽になるはずなのに、なぜか作業が増えている」というものです。
その気づきは、「AIに丸投げするから増える。
工程を分けて頼めば減る」です。
実践ステップは、まず作業フォルダを決め、成果物名を決め、各工程の担当を決めることです。
最初から完璧な自動化を目指さず、1冊分の流れを手動で通してみる。
そこから繰り返す部分をスキルにしていく。
この順番が、初心者にとって一番安全です。





第2章: 初心者向けセットアップと安全設計
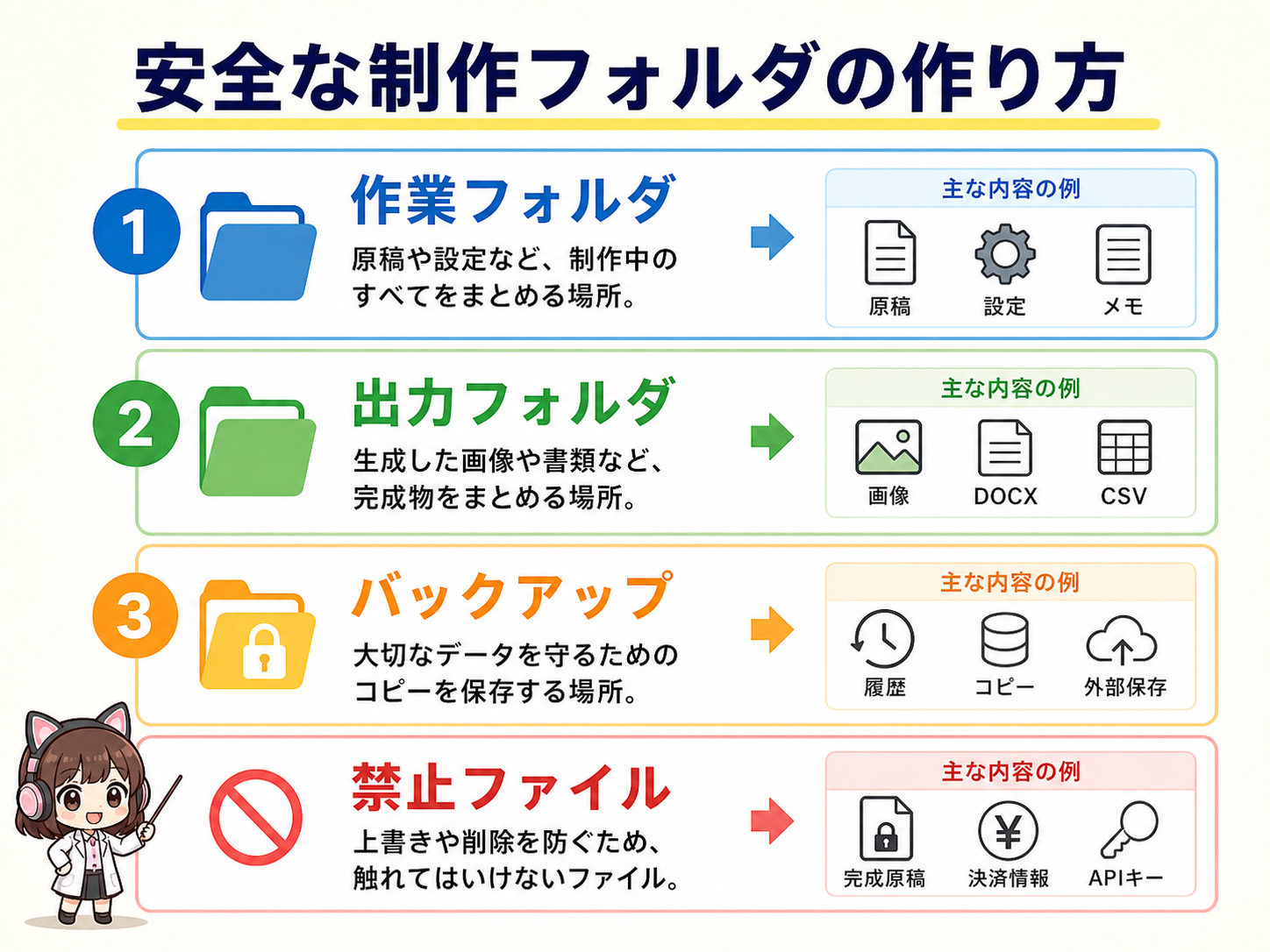
安全な制作フォルダの作り方
AIで電子書籍を作るとき、最初に整えるべきものはプロンプトではありません。
作業場所です。
どのフォルダで作業するのか、生成物をどこに置くのか、何を上書きしてよいのか、何を読ませてはいけないのか。
この土台がないまま進めると、よい原稿ができても後から管理できなくなります。
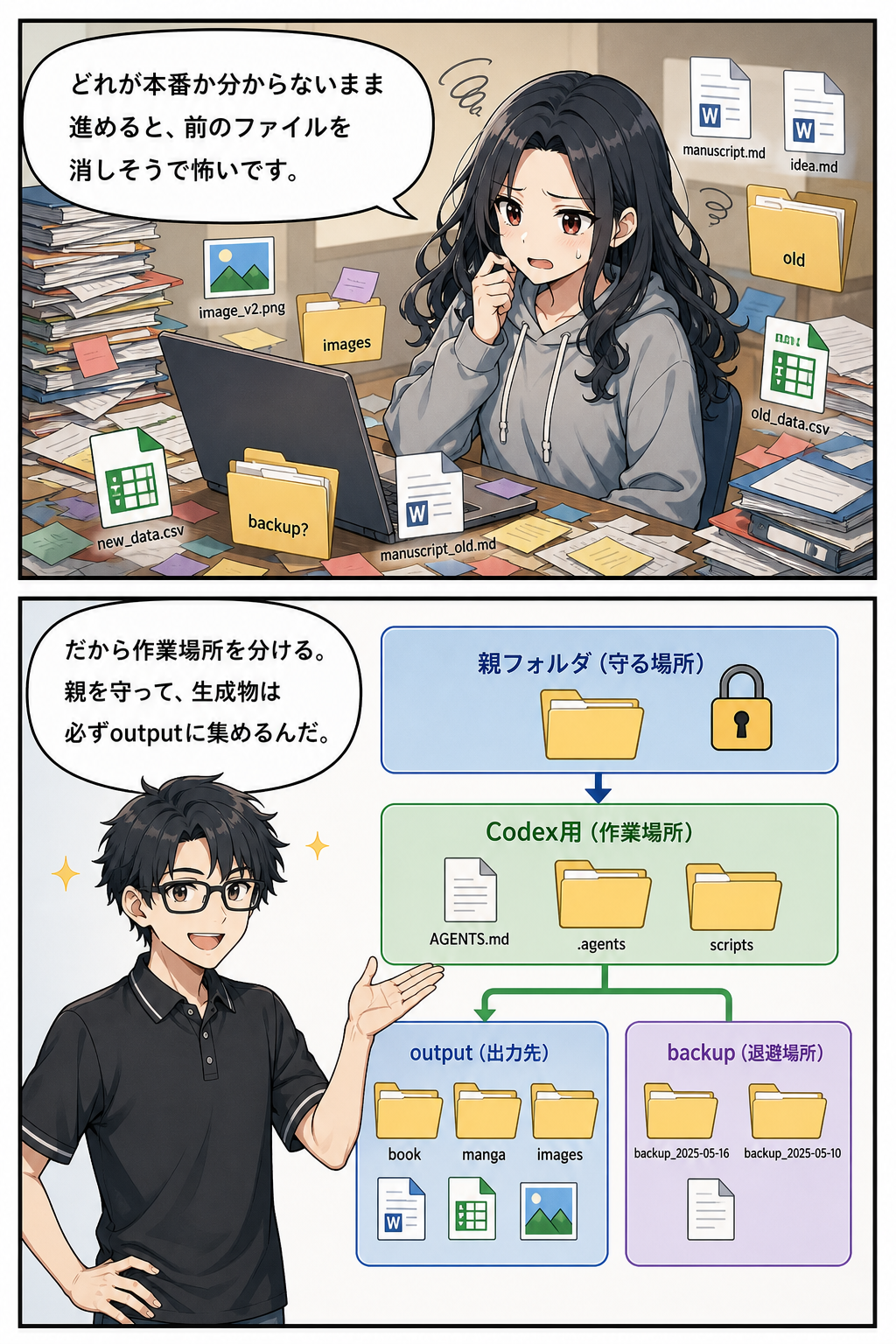
初心者がよくつまずくのは、デスクトップやダウンロードフォルダにファイルを散らしてしまうことです。
`新しい原稿.md`、`修正版.docx`、`最終版2.docx`、`本当に最終.png` のような名前が増えると、AIだけでなく人間も迷います。
コンテンツ制作は、最初からプロジェクトとして扱いましょう。
本書の作業では、出力フォルダを `output/{slug}/` にまとめます。
今回なら `output/claude-code-codex-desktop-content-infinite/` です。
この中に `research.md`、`meta.json`、`manuscript_raw.md` などを置きます。
成果物の場所が決まっていれば、別のエージェントに作業を引き継ぐときも説明が短くなります。
セットアップの基本は、三つあります。
第一に、作業ディレクトリを固定すること。
第二に、ルールファイルを置くこと。
第三に、権限とバックアップの考え方を決めることです。
作業ディレクトリを固定するとは、「この本に関する作業はこのフォルダの中だけで行う」と決めることです。
Claude CodeでもCodexでも、AIに作業場所を明示すると、余計な場所を探しに行くリスクが下がります。
特に親フォルダに別プロジェクトのファイルがある場合は、親フォルダの既存ファイルを上書きしない、というルールを明確にしておきます。
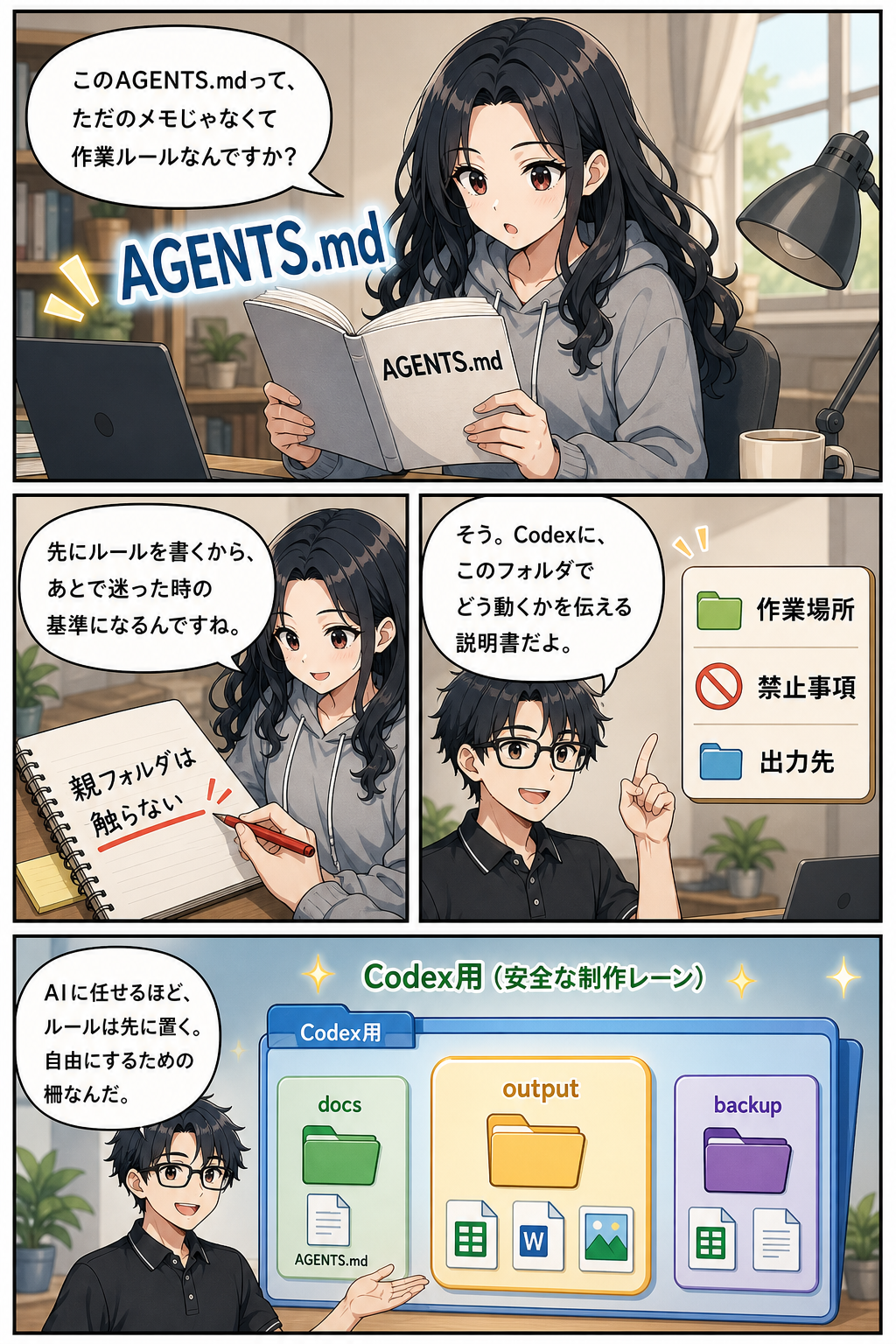
ルールファイルは、AIに毎回読ませる作業説明書です。
Claude Codeでは `CLAUDE.md` というプロジェクト用の指示書がよく使われます。
Codexでは `AGENTS.md` という同じ役割の指示書や、スキル本体である `SKILL.md` を使います。
ここに、作業中のcwd、生成物の保存先、上書き前のバックアップ、画像生成の方法、外部APIキーを使わないことなどを書いておきます。
このルールファイルは、長ければよいわけではありません。
初心者は不安になると、全部を書き込みたくなります。
しかし、ルールが長すぎると、重要な指示が埋もれます。
普遍的な安全ルールは `AGENTS.md` に置き、専門的な作業手順はスキルに分けるのが扱いやすいです。
たとえば、電子書籍の原稿作成は `ebook-manuscript`、図解生成は `ebook-image-gen`、漫画化は `ebook-manga` に分けます。
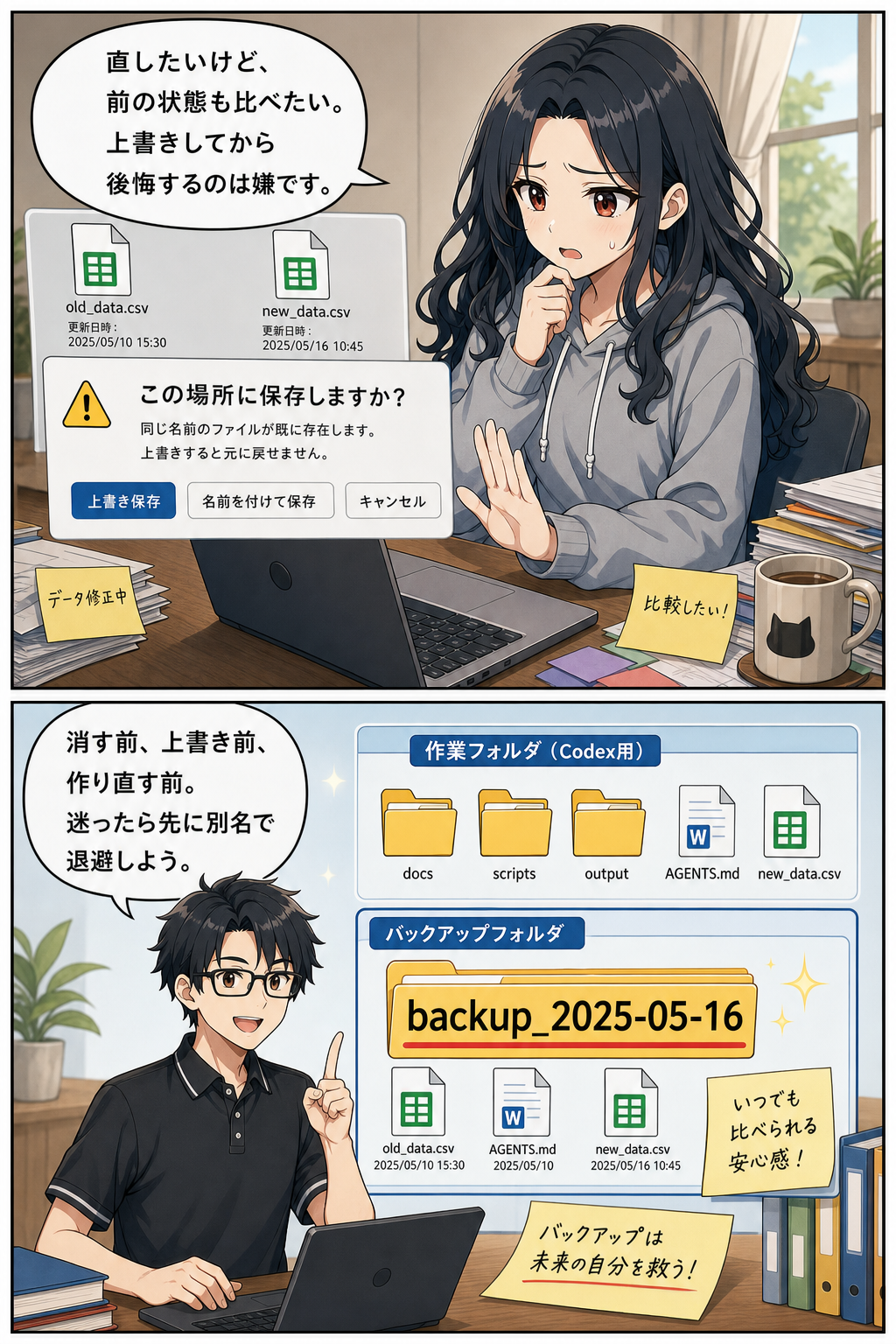
安全設計で特に大切なのは、上書きの扱いです。
原稿、画像、DOCX、CSVは、一度作ると後工程で参照されます。
安易に上書きすると、どの工程からやり直せばよいか分からなくなります。
既存ファイルを更新する場合は、必ず別名バックアップを作ります。
たとえば `manuscript_raw_20260515_backup.md` のように日付を入れると分かりやすいです。
まだ存在しないファイルを新規作成するだけなら、バックアップは不要です。
しかし、`manuscript_raw.md` のような既存成果物を改稿する場合は話が別です。
古い原稿にも価値があります。
新しい原稿が必ずよいとは限りません。
読者の悩みの書き方だけは前のほうが自然だった、ということもあります。
AI時代の制作では、戻れる状態を残すことが品質管理になります。
権限の考え方も重要です。
AIエージェントは、ファイルを読むだけでなく、コマンドを実行したり、ファイルを書き換えたりできます。
便利ですが、危険もあります。
`.env`、APIキー、個人情報、未公開の顧客情報などは、読ませない前提で設計します。
ネットワークアクセスが必要な作業と、ローカルだけで完結する作業も分けます。
Codexの設定では、サンドボックス、承認ポリシー、プロジェクト単位の設定、スキルの有効化などを扱えます。
初心者は細かい設定を一度に覚える必要はありません。
まずは「読ませるファイルを限定する」「書き込む場所を限定する」「危険な操作は確認する」「既存成果物はバックアップする」の四つを守れば十分です。
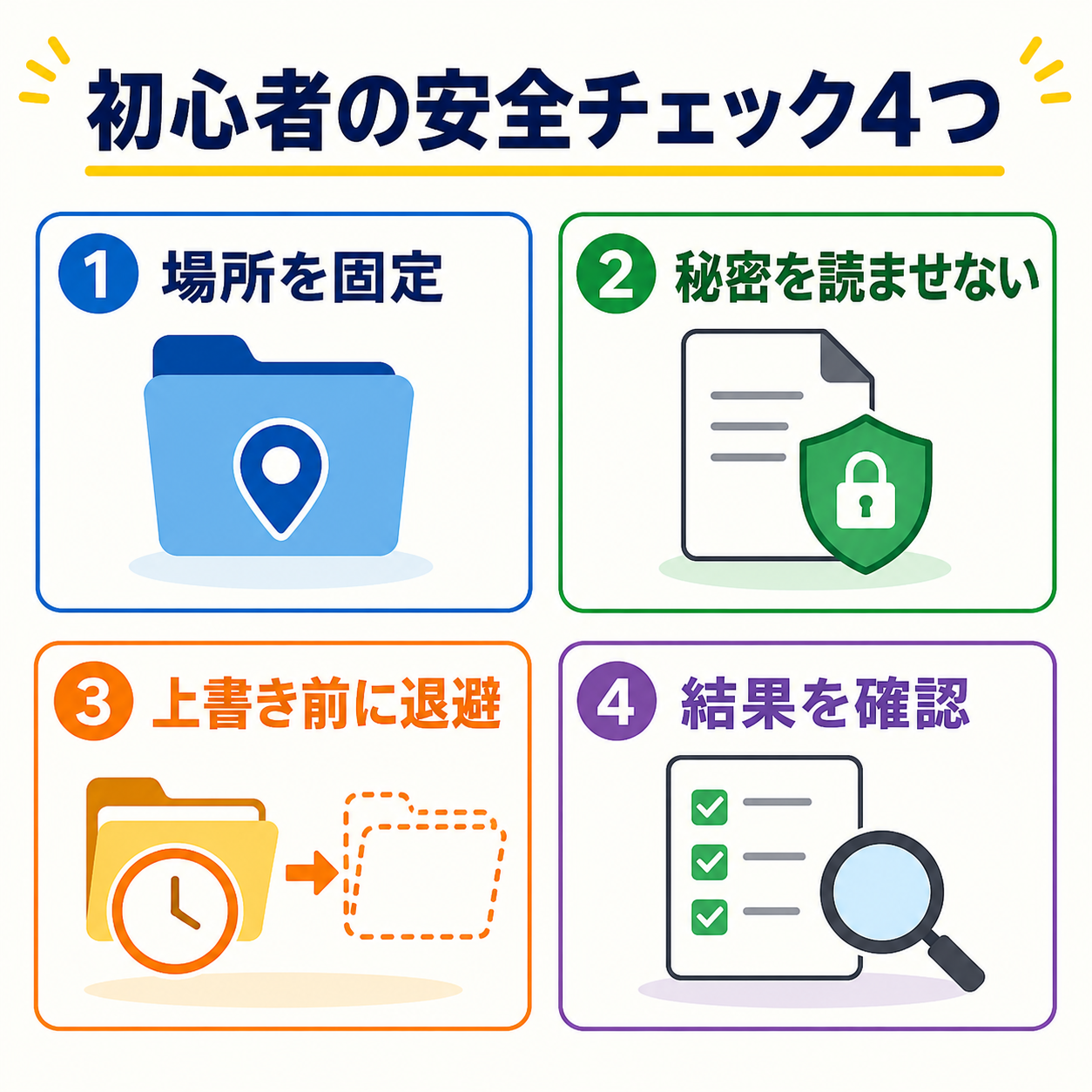
初心者の安全チェック4つ
実践の最初のステップは、作業開始前チェックです。
まず、現在のフォルダを確認します。
次に、対象の出力フォルダを確認します。
次に、これから作るファイルが既存か新規かを確認します。
最後に、参照資料の場所を確認します。
この四つを毎回確認するだけで、事故はかなり減ります。
次に、AIへの依頼文を短く整理します。
「このフォルダで、既存ファイルを不用意に削除・上書きせず、指定の出力先に `manuscript_raw.md` を作成してください」と書けば、作業範囲が明確になります。
そこに「漫画生成はまだ行わない」「図解タグは入れる」「後工程で漫画化しやすい構造にする」といった条件を足します。
初心者が気をつけたいのは、便利なオプションほど後回しにすることです。
権限確認をすべて飛ばす設定、広いフォルダへの書き込み許可、ネットワークの常時許可などは、慣れるまでは使わないほうが安全です。
最初は少し面倒でも、AIが何を読んで何を書いたかを確認する経験が大事です。
安全設計には、ファイル名のルールも含まれます。
AI制作では、途中成果物が増えます。
`research.md`、`manuscript_raw.md`、`manuscript.md`、`image_prompts.md`、`manga_pages.csv` のように役割が分かる名前にしておくと、後工程のエージェントが迷いません。
逆に、`memo.md` や `new.md` のような名前が増えると、どれを参照すべきか分からなくなります。
成果物名を固定することは、AIへの説明を短くする工夫でもあります。
また、確認ログを残す習慣もおすすめです。
たとえば「2026-05-15、公式情報を確認」「第5章のAnthropic公式スキルはGitHub上のREADMEを参照」「料金や対応OSは変わる可能性があるため断定しない」といったメモを残します。
GitHubは、ソースコードやドキュメントを公開、共有できるサービスです。
READMEは、配布元が用意している説明書のような文書です。
出版前の最終確認で、どこを見直せばよいか分かるからです。
AIツールの本は情報が古くなりやすいので、原稿の中でも「確認日時点」「公式ドキュメントで確認してください」という姿勢を持つと安全です。
安全設計は、作業を遅くするためのものではありません。
安心して速く進むための土台です。
作業場所が決まり、バックアップ方針が決まり、成果物名が決まっていれば、原稿担当、図解担当、漫画担当を分けても混乱しません。
つまり安全設計は、後の並列化の準備でもあります。
読者の悩みは、「設定や権限が難しそうで怖い」です。
気づきは、「全部を覚えなくてよい。
作業場所、秘密、上書き、確認だけ押さえれば始められる」です。
実践ステップは、まずプロジェクトフォルダを一つ作り、`output/{slug}/` を決め、`AGENTS.md` に安全ルールを書き、初回は小さな成果物から作ることです。
いきなり漫画つきの完成本を目指すより、まずは `research.md` と `manuscript_raw.md` まで通す。
これが、安全で続けやすい始め方です。


第3章: スキルの説明
スキルとは?
スキルを理解する前に、まずAIの基本を押さえましょう。
AIは、何かを入力すると、それに反応して出力を返すものです。
文章を入れれば文章を返し、条件を入れれば条件に近い答えを返し、素材を入れれば素材をもとに要約や表や画像案を作ります。
ここで大切なのがプロンプトです。
プロンプトとは、期待する結果へ近づけるための指示です。
「小学生にも分かるように説明して」「表にして」「3つの手順に分けて」のような言葉がプロンプトです。
プロンプトは、AIへのお願いというより、結果を近づけるためのハンドルだと考えると分かりやすいです。
ただし、プロンプトだけで毎回作業するのは疲れます。
たとえば、毎回「初心者向けに」「です・ます調で」「図解タグは大きな文字で」「上書き前にバックアップして」「公式LINEの案内は残して」と書くのは大変です。
しかも、毎回少しずつ書き忘れます。
前回は丁寧だったのに、今回は図解の文字が小さい。
前回はバックアップしたのに、今回は忘れる。
こうして品質がぶれます。
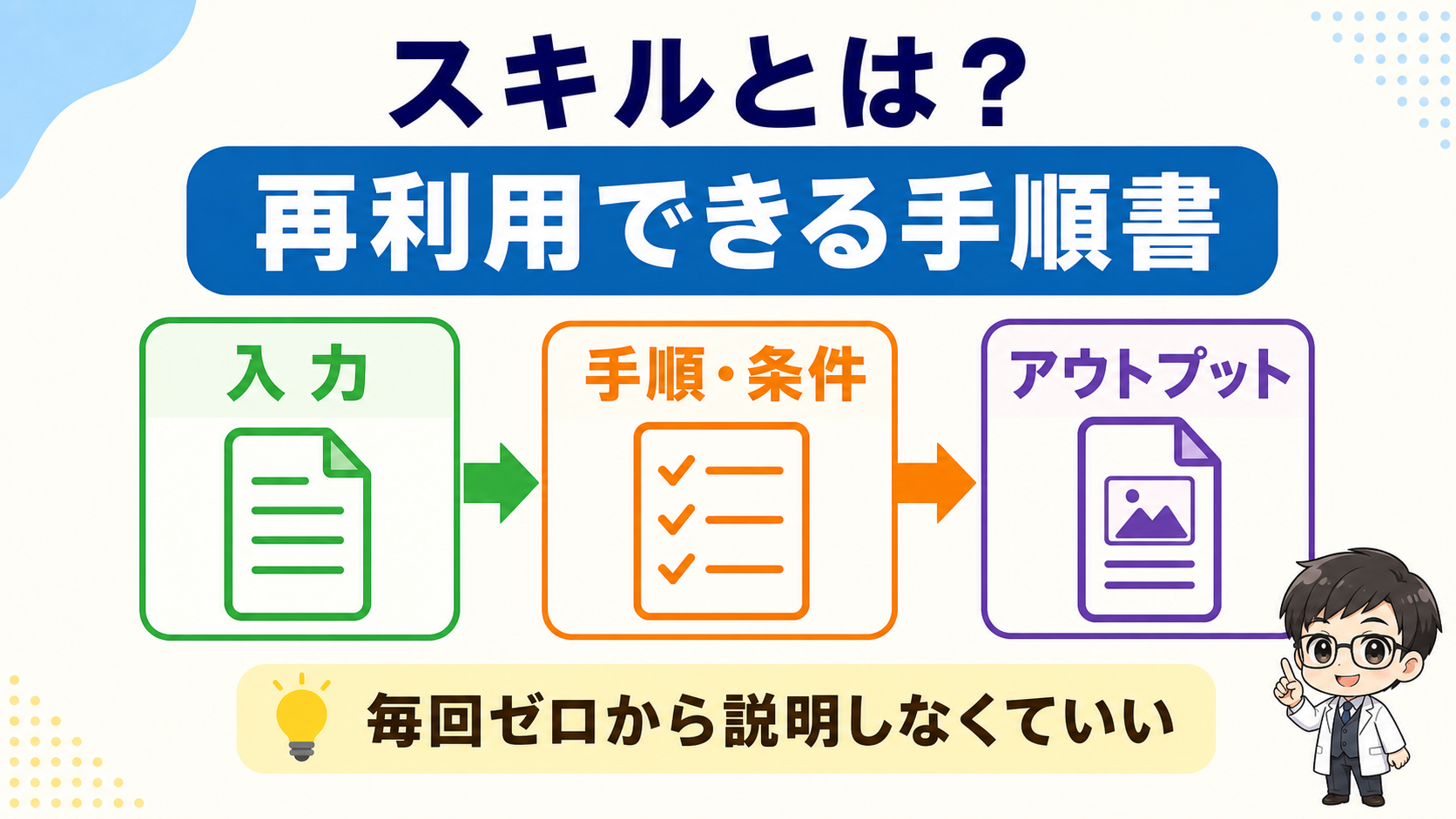
スキルは、このぶれを減らすための再利用できる手順書です。
料理でいえばレシピ、レジでいえば会計手順、編集部でいえば原稿チェックリストです。
特定のタスクをこなすための手順、指示、条件、出力形式をひとまとめにしたものがスキルです。
スキルの実体は、多くの場合 `SKILL.md` というMarkdownファイルです。
Markdownは、見出しや箇条書きを普通のテキストで書ける文書形式です。
`SKILL.md` には、「この作業は何を入力にするか」「何を出力するか」「どの順番で進めるか」「何をしてはいけないか」「完成したら何を報告するか」を書きます。
スキルを一言で言うなら、「毎回ゼロから説明しなくていいようにする箱」です。
箱の中には、手順、条件、素材、出力形式が入っています。
ユーザーがテーマや素材を渡すと、エージェントがその箱を開き、必要な手順を読んで作業します。
たとえば、レジスキルを想像してください。
お客さんが買う商品は毎回違います。
プリン、サンドイッチ、コーラの日もあれば、お弁当とお茶の日もあります。
でも、会計の手順は同じです。
商品を読み取る、合計する、支払いを受ける、レシートを渡す。
この「商品は変わるが、手順は変わらない」という部分がスキルに向いています。
電子書籍制作でも同じです。
テーマは毎回変わります。
「AI副業」「時間管理」「英語学習」「SNS運用」など、入力素材は変わります。
しかし、読者の悩みを整理し、章立てを作り、初心者向けに本文を書き、図解タグを入れ、最後に確認するという手順は大きく変わりません。
だから、電子書籍制作はスキル化に向いています。
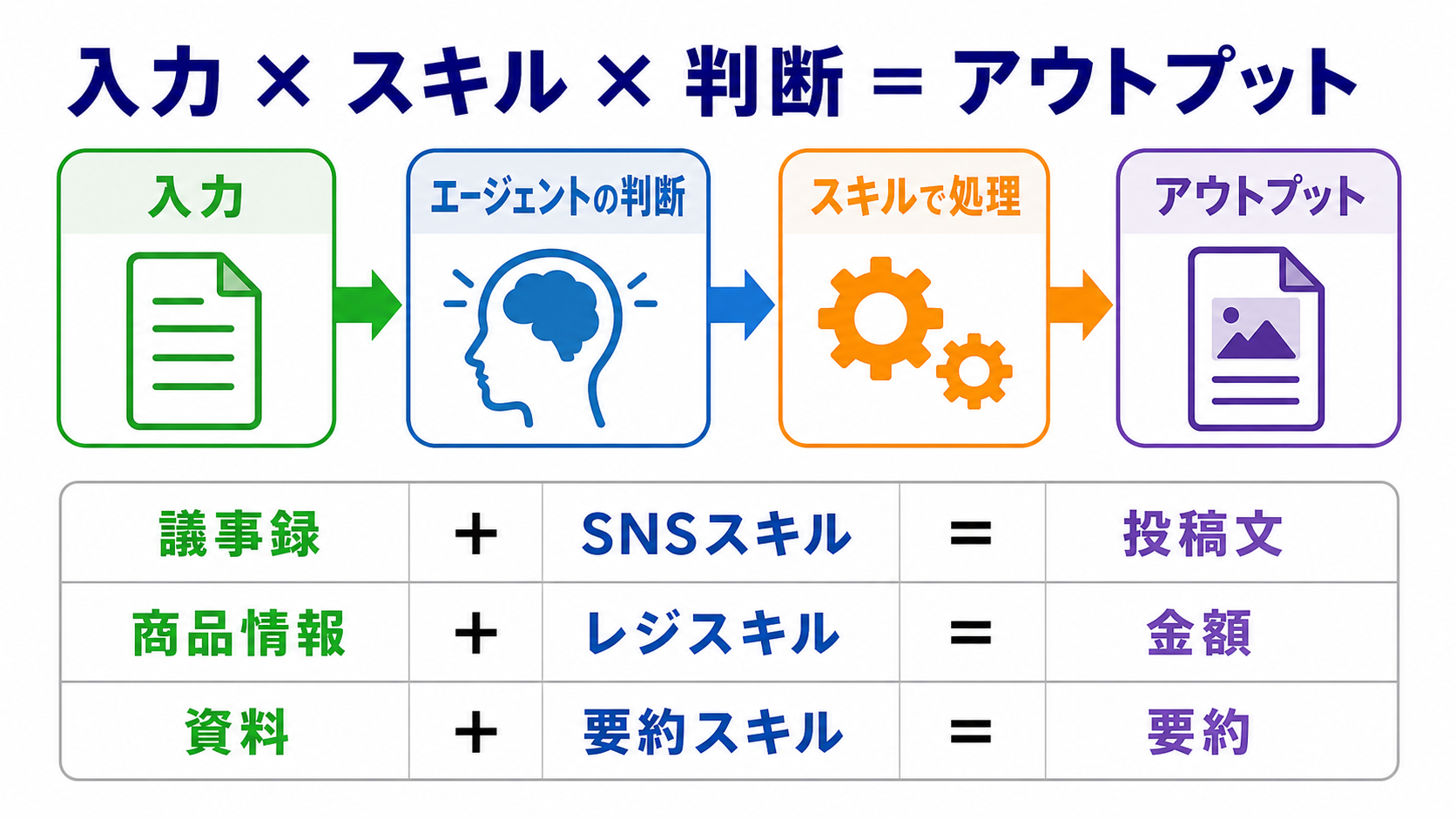
入力 × スキル × 判断 = アウトプット
スキルにできる作業には、三つの条件があります。
第一に、自分が何度もやっていること。
第二に、手順を説明できること。
第三に、結果を確認できることです。
この三つがそろっていれば、スキル化しやすい作業です。
反対に、スキルにしにくい作業もあります。
自分でもよく分かっていない作業、手順を説明できない作業、正解を判断できない作業です。
たとえば、税務をまったく知らない人が「税務判断スキル」を作るのは危険です。
自分が判断できないものを、そのままAIに渡すと、間違いにも気づけません。
スキルは魔法ではなく、あなたが仕事でできることを手順化して再利用するものです。
初心者が最初に作るべきスキルは、難しいものではありません。
おすすめは、すでに自分が何度もやっている小さな作業です。
毎週の議事録要約、SNS投稿の下書き、原稿の誤字チェック、画像タグの確認、請求書の項目チェックなどです。
特に「作ったあとに毎回確認していること」はスキルに向いています。
AIは抜け漏れを探す作業が得意だからです。
スキルを作るときは、仕事を五つに分けて考えると整理しやすくなります。
集める、考える、作る、確かめる、渡す。
この五つです。
リサーチは「集める」、構成づくりは「考える」、原稿執筆は「作る」、レビューは「確かめる」、DOCXや販売素材への整理は「渡す」に近い作業です。
自分の作業がどこにあるか分かると、スキルの範囲も決めやすくなります。
本書のワークフローでは、スキルを工程別に分けます。
`ebook-research` は読者の悩みと材料を集めるスキルです。
`ebook-manuscript` は原稿を作るスキルです。
`ebook-image-gen` は図解プロンプトを作るスキルです。
`ebook-manga` は漫画化のシナリオやCSVを作るスキルです。
`ebook-docx` は最終DOCXにまとめるスキルです。
どれも「何でもやる巨大スキル」ではなく、担当範囲が決まっています。
スキルの基本項目は、次のように考えます。
| 項目 | 初心者向けの意味 | 例 |
|---|---|---|
| 目的 | 何のための手順か | 初心者向け原稿を作る |
| 入力 | 何を材料にするか | `research.md`、`meta.json` |
| 出力 | 何を完成物にするか | `manuscript_raw.md` |
| 手順 | どの順番で進めるか | 章立て、本文、図解タグ、確認 |
| 禁止 | 何をしないか | 既存ファイルを無断上書きしない |
| 完了条件 | どこまでできたら終わりか | 文字数、図解タグ、報告内容 |
ここで混乱しやすいのが、プロンプトとスキルの違いです。
プロンプトは今回の依頼です。
スキルは毎回使う手順です。
「今回のテーマはClaude CodeとCodexです」はプロンプトです。
「初心者向けに、読者の悩みから始め、図解タグを入れ、公式LINEのプレースホルダーを残す」はスキルに入れるべき作業標準です。

プロンプトとスキルの違い
スキルには、後工程を助ける役割もあります。
原稿スキルが図解タグを具体的に書いておけば、画像生成スキルは迷いません。
原稿スキルが読者の悩み、気づき、実践ステップを本文に自然に入れておけば、漫画スキルは場面化しやすくなります。
スキル同士が会話するわけではありません。
エージェントがスキルを読み、成果物を次の工程へ渡すことでつながります。
たとえば第6章でDigicomicワークフローを書く場合、ただ「リサーチして原稿を書きます」と説明するだけでは漫画化しにくいです。
「読者がAI副業に迷っている」「リサーチで悩みが整理される」「原稿で順番が見える」「図解で工程が見える」「漫画で感情の変化が伝わる」「DOCXで商品になる」と書くと、漫画担当は場面を作れます。
スキルは、文章の構造にも影響するのです。
スキルを改善するタイミングは、失敗した直後です。
図解が細かすぎたら、画像タグのルールに「主要ラベル3〜5個」と足します。
原稿が煽りすぎたら、文体ルールに「実務的でやさしい」と足します。
漫画で読みにくいコマ順になったら、日本漫画ルールを明記します。
失敗をスキルへ戻すことで、次の制作の精度が上がります。
ただし、スキルを増やしすぎると管理が難しくなります。
似たスキルが複数あると、どれを使うべきか迷います。
初心者のうちは、入口スキル、工程別スキル、補助スキルの三種類に分けると整理しやすいです。
入口スキルは全体の流れを指示します。
工程別スキルはリサーチ、原稿、図解、漫画、DOCXを担当します。
補助スキルは画像生成やスライド風図解など、必要なときだけ使います。
スキルは、AIに命令するためだけのものではありません。
自分自身の作業理解を深めるためのメモでもあります。
`SKILL.md` を書こうとすると、「この工程の入力は何か」「完成とは何か」「禁止事項は何か」を考えることになります。
この整理こそが、制作の品質を上げます。
読者の悩みは、「毎回プロンプトを考えるのがつらい」です。
気づきは、「よく使う依頼はスキルにして、毎回変わるテーマだけ渡せばよい」です。
実践ステップは、まず一番繰り返す作業を一つ選び、入力、出力、手順、禁止事項、完了条件を書き出すことです。
最初のスキルは完璧でなくて構いません。
1回使い、失敗を見つけ、少し直す。
その繰り返しで、あなた専用の制作チームが育っていきます。





第4章: エージェントの説明
エージェントとサブエージェントの役割
エージェントとは、状況を見て判断し、必要な作業を進めるAIの担当者です。
普通のチャットAIは、質問に答えることが中心です。
エージェントは、それより一歩進んで、目的を理解し、必要なファイルを読み、使うスキルを選び、実行し、結果を確認しながら進みます。
人間の仕事にたとえると、エージェントは「判断して動く担当者」です。
あなたが「この原稿を初心者向けに直して」と頼むと、エージェントは対象ファイルを確認し、追加資料を読み、どこを直すべきか考え、必要ならバックアップを作り、本文を改稿し、最後に変更点を報告します。
単に答えを返すだけではなく、作業の流れを持って動くのがエージェントです。
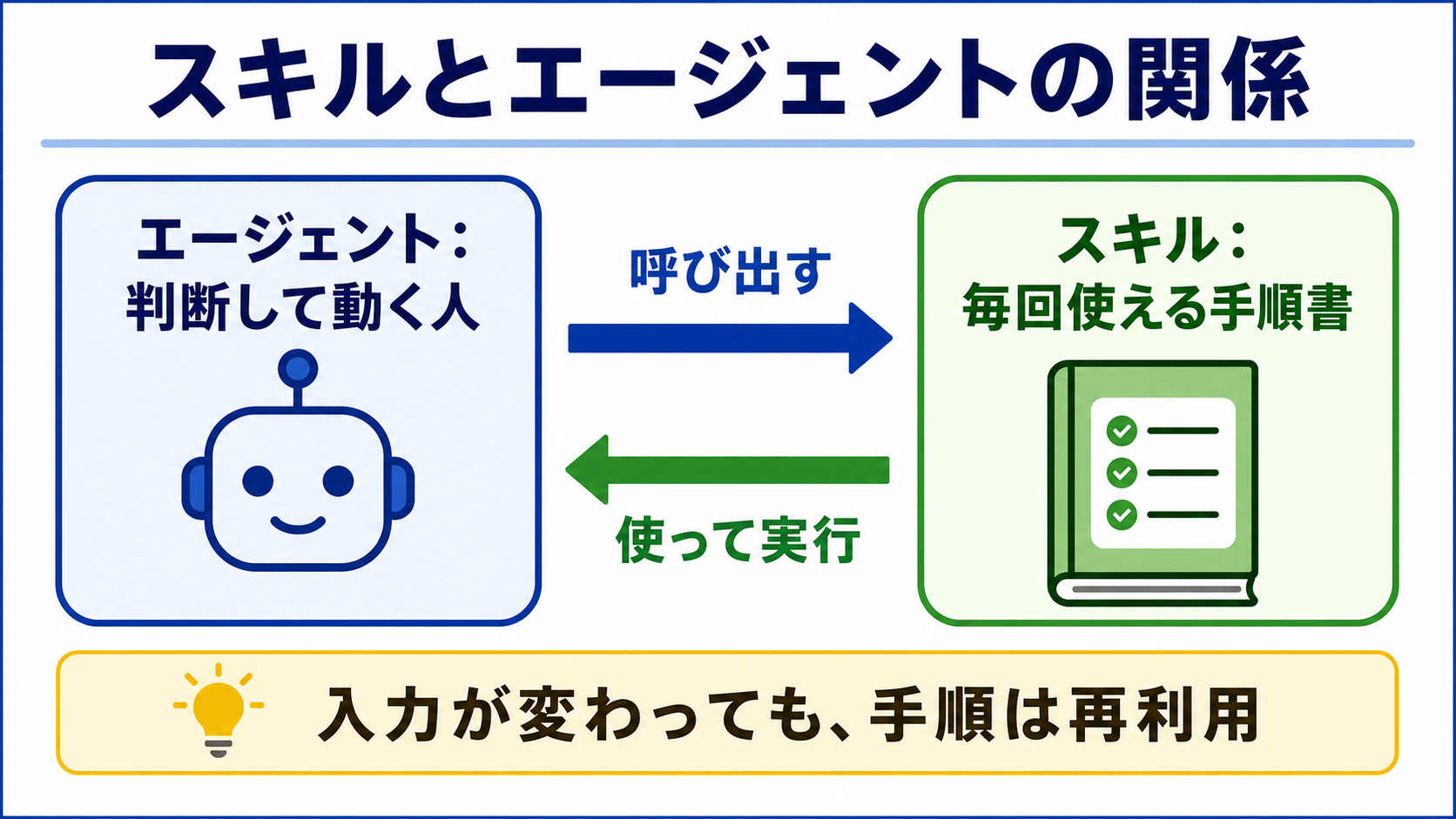
スキルとの違いもここで整理しましょう。
スキルは手順書です。
エージェントはその手順書を読んで動く担当者です。
`ebook-manuscript` は原稿を書くための手順書です。
原稿作成担当エージェントは、その手順書を読み、`research.md` や `meta.json` を材料にして、実際に `manuscript_raw.md` を作ります。
つまり、スキルは「どうやるか」、エージェントは「誰が判断して進めるか」です。
この二つを混ぜると混乱します。
スキル同士が会話して仕事をするわけではありません。
エージェントやサブエージェントが、必要なスキルを読んで仕事をします。
スキルとエージェントの関係
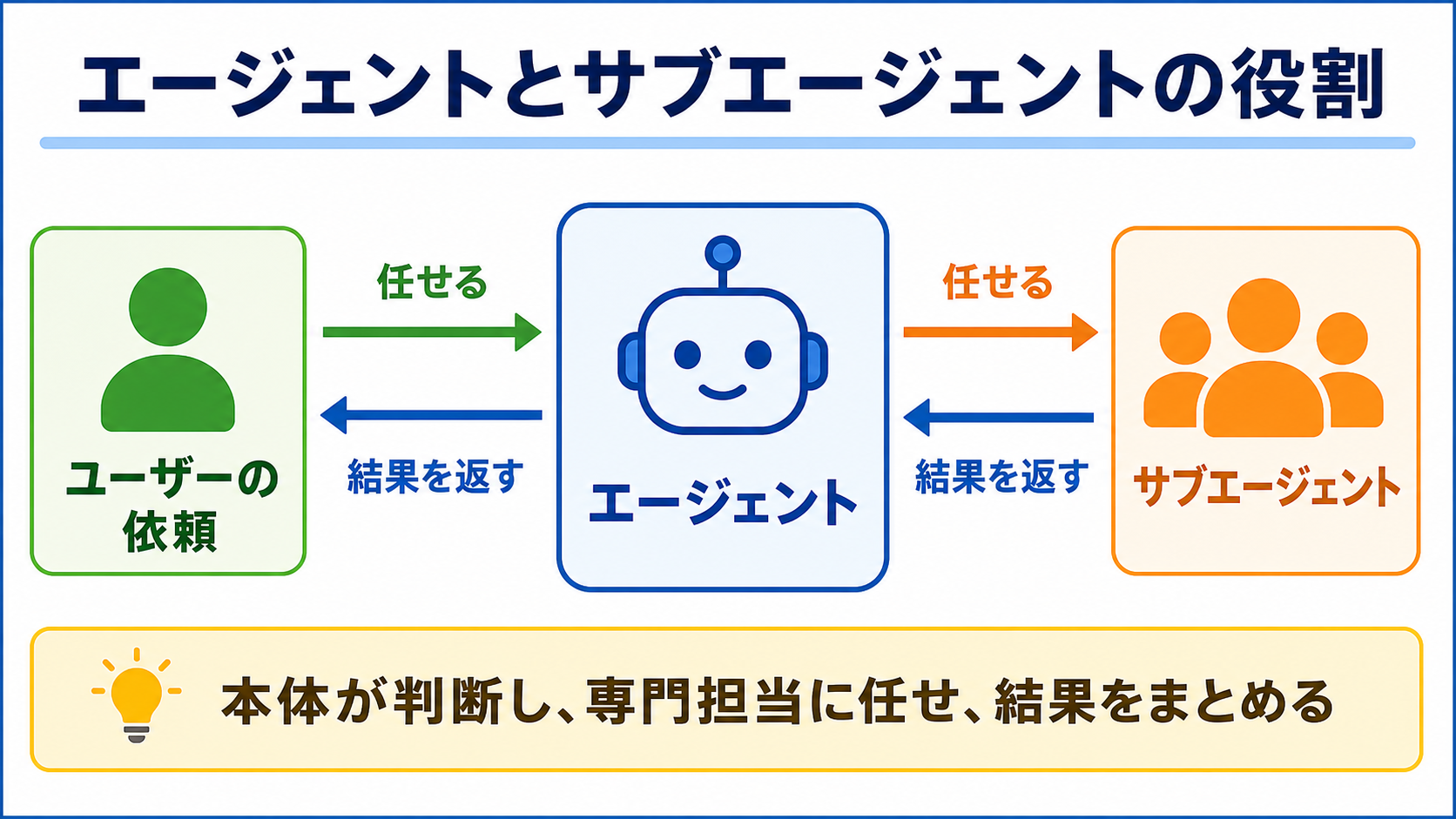
ここに、サブエージェントという考え方が加わります。
サブエージェントは、メインのエージェントが必要なときに呼び出す別の専門担当です。
会社でいえば、メインエージェントがプロジェクトマネージャー、サブエージェントが調査担当、レビュー担当、コード確認担当、要約担当のような存在です。
サブエージェントが便利なのは、別の部屋で作業できるからです。
大量の資料を読む調査、大きなコードベースの確認、長い原稿のレビューを、メインの会話に全部流し込むと、重要な指示が埋もれます。
サブエージェントに任せると、途中の大量情報は別の作業場で処理され、メインエージェントには結果の要約だけが戻ります。
初心者向けには、机のたとえが分かりやすいです。
メインエージェントの机に、資料、メモ、エラー全文、画像案、レビュー指摘を全部置くと、机が散らかります。
サブエージェントは別の机で資料を広げ、必要な結論だけを持って戻ってきます。
これにより、メインエージェントは全体の判断を保ちやすくなります。
ただし、サブエージェントは無料で無限に使える魔法ではありません。
別のAI担当者を動かすので、処理量や時間は増えます。
使うべき場面は、大量の調査、並列レビュー、長いファイル確認、専門性の高い一部作業などです。
短い質問や小さな修正なら、メインエージェントだけで進めたほうが簡単です。
エージェント、サブエージェント、スキル、ルールファイルの関係を表にすると、次のようになります。
| 用語 | 初心者向けのたとえ | 役割 |
|---|---|---|
| エージェント | 判断して動く担当者 | 全体を見て、手順を選び、結果をまとめる |
| サブエージェント | 別の専門担当 | 調査、レビュー、要約など一部を別作業場で担当する |
| スキル | 毎回使える手順書 | 同じ品質で作業するための手順を渡す |
| `AGENTS.md` / `CLAUDE.md` | 会社の共通ルール | プロジェクト全体で毎回守るルールを書く |
| MCP | 外部ツールへの接続口 | Google DriveやGitHubなどにつなぐ仕組み |
`AGENTS.md` と `CLAUDE.md` は、エージェントそのものではありません。
プロジェクトで守るルールを書いた指示書です。
`AGENTS.md` はCodexでよく使う指示書、`CLAUDE.md` はClaude Codeでよく使う指示書です。
どちらも「このフォルダではこう作業してください」と伝えるためのものです。
MCPは、Model Context Protocolの略で、AIが外部ツールやサービスとやりとりするための接続口です。
たとえばGoogle Drive、GitHub、Figmaなどに接続する仕組みを指します。
初心者は最初から詳しく覚える必要はありません。
「外部サービスにつなぐための仕組み」とだけ理解しておけば十分です。
Codexのような環境では、複数の担当を並行して動かす考え方も出てきます。
たとえば、メインエージェントがスキル構成を改善している間に、原稿レビュー担当が `manuscript_raw.md` を改稿する。
別のレビュー担当が、完成後に章立てと事実確認を見る。
さらに後で漫画担当が `manuscript.md` を読み、`manga_pages.csv` を作る。
このように分担すれば、一冊の制作が止まりにくくなります。
ただし、並行作業には危険もあります。
同じファイルを二人のエージェントが同時に書き換えると、片方の変更が失われることがあります。
だから、担当と成果物を分けます。
原稿担当は `manuscript_raw.md` を作る。
スキル改善担当は `.agents/skills/` を調整する。
漫画担当は後で `manga_pages.csv` を作る。
担当範囲が明確なら、衝突は減ります。
エージェントに頼むときは、肩書きだけでは不十分です。
「あなたはプロの編集者です」だけでは、何を出力すべきか分かりません。
よい依頼には、担当、目的、入力、出力、禁止事項、完了報告が入ります。
たとえば「あなたは原稿作成担当です。
漫画生成はまだ行わず、リサーチから原稿作成まで進めてください。
出力は `manuscript_raw.md` です」と書くと、作業が明確になります。

よいエージェント依頼の5要素
エージェント運用で大切なのは、完成物ではなく引き継ぎ物を見ることです。
原稿担当が作った原稿は、読者に見せる完成品であると同時に、図解担当と漫画担当への材料です。
だから本文には、読者の悩み、気づき、行動が自然に含まれている必要があります。
漫画担当は、その変化をコマにします。
読者が「AI副業が怖い」と悩み、「工程を分ければよい」と気づき、「まず作業フォルダを作る」と動く。
この流れがあると、漫画にしやすくなります。
レビュー担当も重要です。
AIが作った文章は、読みやすく見えても、古い情報や強すぎる断定を含むことがあります。
特にAIツールの名称、料金、対応OS、公式機能は変わりやすいです。
本文では「確認日時点」「公式情報を確認する」「環境によって異なる」といった書き方を使い、必要な事実は後で再確認できるようにします。
エージェントにレビューを頼むときは、「事実」「表現」「構成」「後工程への渡しやすさ」を分けて見てもらうと効果的です。
エージェントを増やすほど、ディレクションが大切になります。
人間のあなたは、すべてを手で作る必要はありません。
しかし、何を作るか、誰に渡すか、どこまでできたら完了かは決める必要があります。
AI時代の副業では、作業者として頑張るより、制作ディレクターとして工程を整える力が価値になります。
このとき、エージェントに自由を与えすぎないことも大切です。
「いい感じに全部作って」ではなく、「今回は漫画生成はしない」「原稿を上書きする場合はバックアップ」「図解タグは維持」「章末の要点欄は作らず本文に自然に入れる」のように、境界線を置きます。
境界線があるから、エージェントは安心して動けます。
エージェントの良い使い方は、作業を小さく渡し、結果を確認し、次へ渡すことです。
リサーチが終わったら原稿へ。
原稿が終わったら図解へ。
図解が終わったらDOCXへ。
漫画化は原稿の構造が整ってから。
各工程で成果物を見れば、どこで品質が落ちたか分かります。
読者の悩みは、「AIエージェントと言われても、自分には難しそう」です。
気づきは、「エージェントは専門家風の魔法ではなく、役割を分けた作業者として考えればよい」です。
実践ステップは、最初に三つだけ担当を作ることです。
リサーチ担当、原稿担当、レビュー担当。
この三つで一冊の土台を作り、慣れたら図解担当と漫画担当を追加します。
役割が増えるほど、あなたは作業者からディレクターへ近づいていきます。




第5章: スキルとエージェントを活用した事例
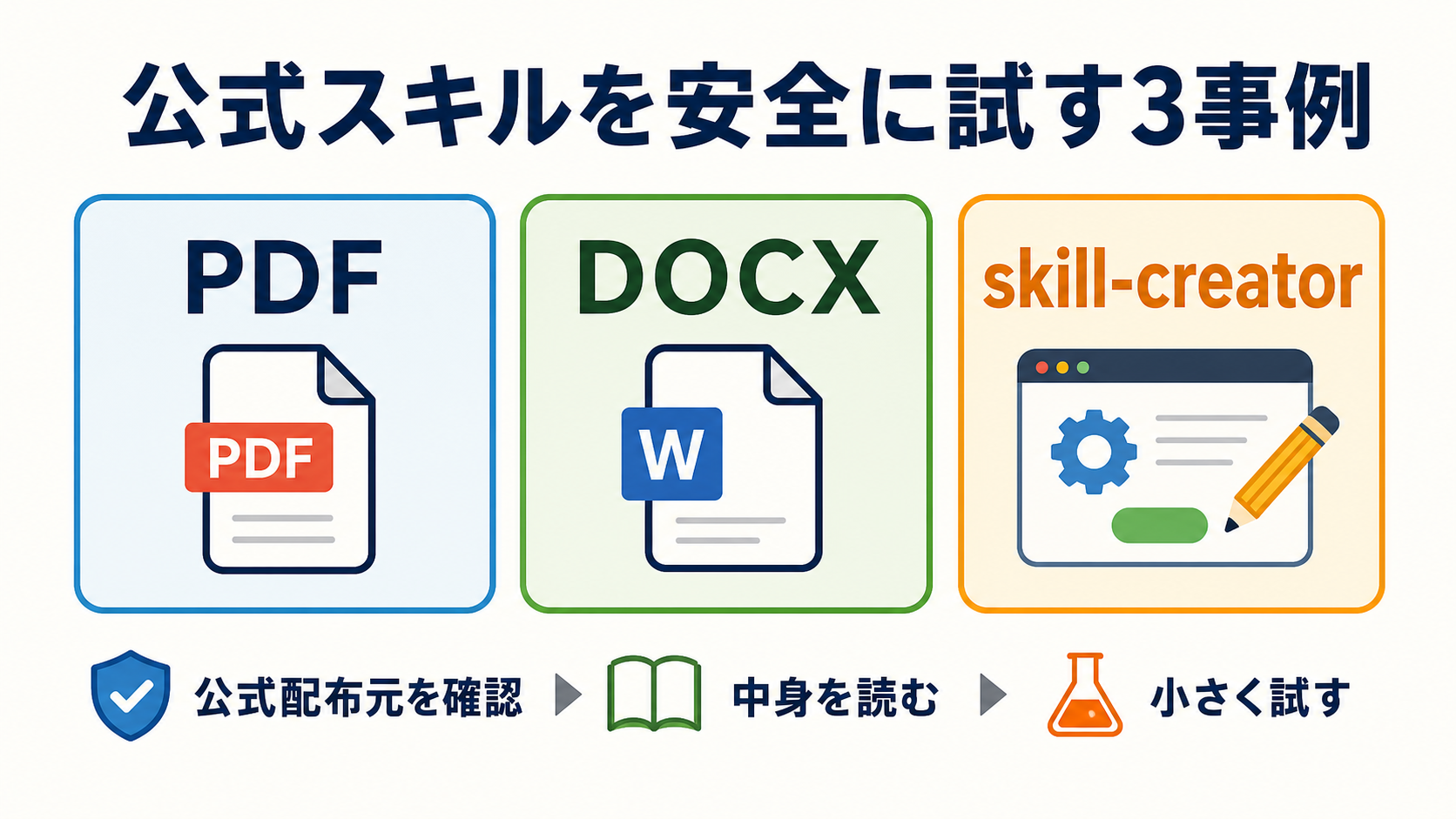
公式スキルを安全に試す3事例
スキルの考え方が分かっても、最初から自分で全部作るのは大変です。
そこで参考になるのが、Anthropic公式の `anthropics/skills` リポジトリです。
このリポジトリには、Claudeのスキルシステムで使えるさまざまなスキル例が公開されています。
`pdf`、`docx`、`pptx`、`xlsx`、`skill-creator` など、実務に近いものも含まれています。
ここで大切なのは、「公式だから何も確認しなくてよい」ではない、ということです。
公式配布元は信頼性の高い出発点ですが、導入前には必ず中身を確認します。
スキルは、ただの説明文ではなく、スクリプトや補助ファイルを含むことがあります。
ローカルファイルを読む、変換する、外部ツールを呼ぶ、といった処理が含まれる場合もあります。
だから、配布元、ライセンス、README、`SKILL.md`、実行されるスクリプトを確認してから使います。
ライセンスは、その素材をどこまで利用してよいかを示す利用条件です。
`anthropics/skills` のREADMEでは、スキルは「instructions, scripts, resources」を含むフォルダとして説明されています。
これは、指示文、実行用の小さなプログラム、参考資料をまとめたもの、という意味です。
つまり、スキルはAIの口調を変えるだけのものではありません。
特定の作業を繰り返し実行しやすくするためのパッケージです。
公式リポジトリには、ドキュメント作成や編集に使われるスキルも含まれていますが、一部は参考用のsource-availableとして扱われています。
source-availableとは、中身は見られるが、使い方や再配布には条件がある形式です。
商用利用や再配布の前には、必ずライセンスを確認しましょう。
Claude Codeで公式スキルを試す考え方は、まずマーケットプレイスや公式リポジトリから入手し、必要なスキルだけをインストールし、小さなファイルで動作確認することです。
いきなり大事な原稿や顧客資料に使うのではなく、サンプルPDF、サンプルDOCX、テスト用フォルダで試します。
うまく動くことが分かってから、自分の制作フローに組み込みます。
公式READMEでは、Claude Codeで `anthropics/skills` をプラグインマーケットプレイスとして追加し、`document-skills` や `example-skills` のような単位でインストールする流れが案内されています。
コマンド例としては `/plugin marketplace add anthropics/skills`、必要に応じて `/plugin install document-skills@anthropic-agent-skills` のような形です。
ただし、実際に使うときは最新の公式READMEを確認してください。
インストール手順は更新される可能性があるため、本書では「公式配布元を確認し、必要なスキルだけを小さく試す」という考え方を中心に覚えておきます。
事例1は `pdf` スキルです。
Kindle副業では、参考資料がPDFで配布されていることがあります。
セミナー資料、白書、利用規約、調査レポートなどです。
初心者はPDFを開いて目で読むだけで疲れてしまいます。
`pdf` スキルを使うと、PDFからテキストや構造を読み取り、要約や論点整理に使いやすくなります。
ただし、PDFをAIに読ませるときは、著作権と引用に注意します。
PDFに書かれている文章をそのまま長く転載してはいけません。
自分の本では、要点を自分の言葉で整理し、必要な場合は出典を明記します。
PDFスキルの役割は、資料を丸写しすることではなく、読者の悩みを理解するための材料整理です。
実践の流れはこうです。
まず、公式配布元から `pdf` スキルの内容を確認します。
次に、テスト用PDFを一つ用意します。
エージェントには「このPDFから、Kindle初心者が知るべき論点を5つに整理してください。
本文への転載ではなく、要約と自分の解説用メモにしてください」と頼みます。
出力は `research_sources.md` のような補助ファイルに保存します。
こうすれば、後の `research.md` に安全に統合できます。
事例2は `docx` スキルです。
電子書籍制作では、最終的にWord形式のDOCXが必要になることがあります。
文章をMarkdownで書き、最後にDOCX化する流れは効率的ですが、見出し、画像、ページ区切り、フォント、余白などでつまずきます。
`docx` スキルは、Word文書の作成や編集の考え方を学ぶ参考になります。
DOCXスキルを使うときの読者の悩みは、「原稿はできたのに商品ファイルにならない」です。
気づきは、「原稿本文と組版作業は別工程にしたほうがよい」です。
原稿担当は読みやすいMarkdownを作ります。
DOCX担当は見出し、画像、ページ設定、フォントを整えます。
これを分けるだけで、作業がかなり楽になります。
実践の流れは、まず短いサンプル原稿をDOCXに変換することです。
いきなり30,000字の本を変換しません。
見出しがどう表示されるか、画像がどこに入るか、余白が詰まりすぎないかを確認します。
問題があれば、原稿側の書き方を直すのか、DOCX化スキル側の手順を直すのかを分けて考えます。
事例3は `skill-creator` です。
これは、自分専用のスキルを作るときに役立つ考え方です。
副業で本当に価値が出るのは、既存スキルを使うだけでなく、自分の作業に合わせてスキルを育てることです。
たとえば「デジコミック用のリサーチスキル」「漫画化しやすい原稿スキル」「図解タグ生成スキル」のように、自分の制作物に特化したレシピを作れます。
`skill-creator` を使うときは、いきなり大きなスキルを作らせるのではなく、困っている作業を一つだけ選びます。
「毎回、画像タグの指定がぶれる」「漫画の吹き出しルールを忘れる」「DOCX化の前に画像抜けを確認したい」などです。
その悩みを伝え、入力、出力、禁止事項、完了条件を整理してもらいます。
できた `SKILL.md` は、そのまま使う前に必ず読みます。
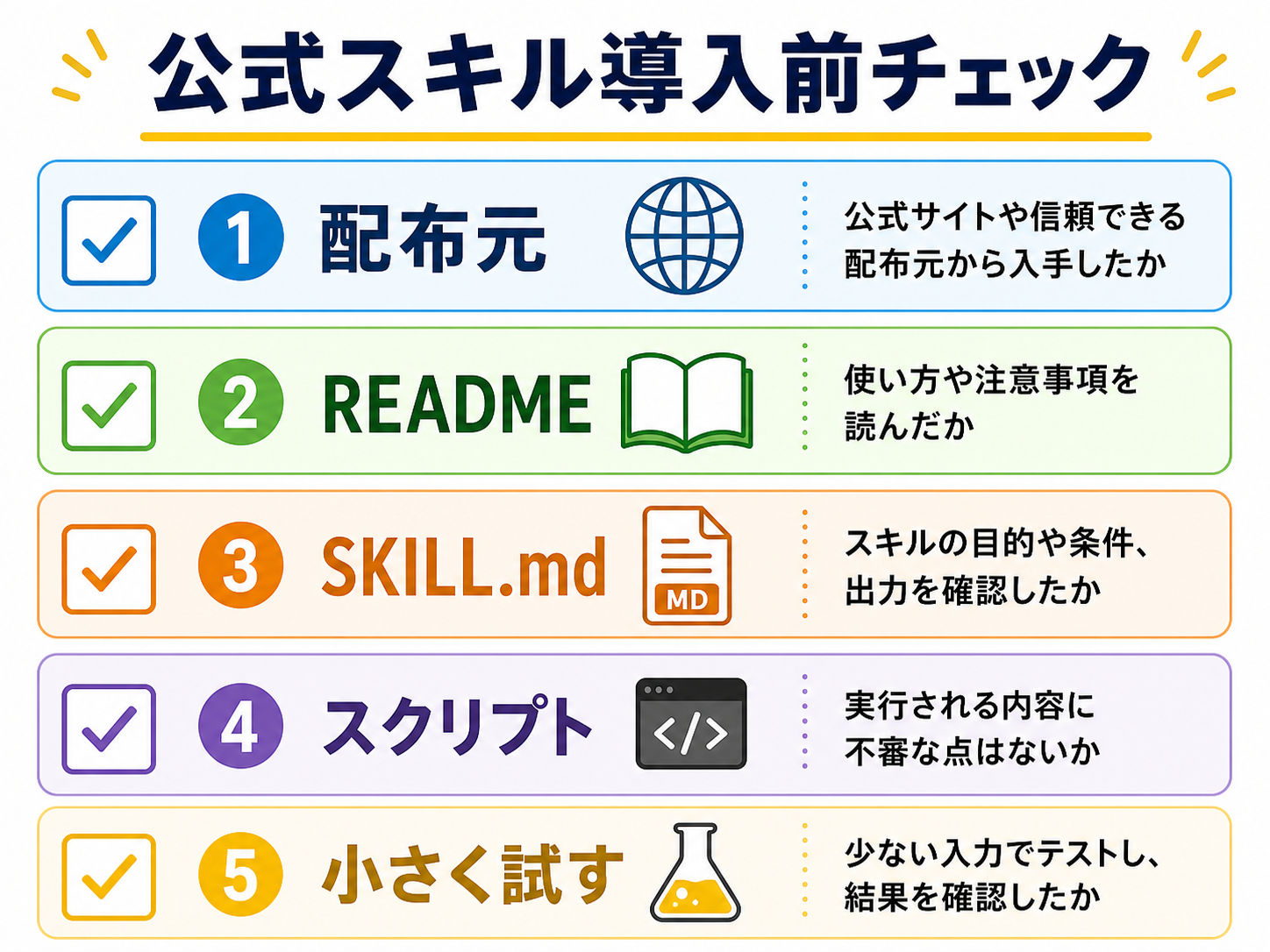
公式スキル導入前チェック
公式スキルの安全性については、三段階で考えます。
第一に、配布元を確認します。
公式GitHub、公式ドキュメント、信頼できるマーケットプレイスかを見ます。
第二に、中身を確認します。
`SKILL.md` に何が書かれているか、どのスクリプトが実行されるか、外部通信やファイル削除がないかを見ます。
第三に、小さく試します。
サンプルファイルで動かし、期待通りの出力になるかを確認します。
初心者が避けたいのは、誰かが配布しているスキルを中身を読まずに入れることです。
AI制作では、スキルが作業手順そのものになります。
悪意がなくても、あなたの作業環境に合わない手順が含まれていることがあります。
たとえば、既存ファイルを上書きする設計、外部APIキーを使う設計、ローカルで画像を生成する設計などです。
本書のワークフローでは、画像生成はCodexやChatGPTの `image_gen` を使い、外部画像生成APIや `.env` は使わない方針です。
スキルがこの方針に合うかを確認します。
公式スキルを自分の制作に取り込むときは、「そのまま使う部分」と「自分用に変える部分」を分けます。
たとえば `pdf` スキルの資料抽出の考え方は参考になりますが、Kindle原稿に使うなら、抽出結果を必ず `research.md` の補助材料として扱うルールを足します。
`docx` スキルの文書生成の考え方は参考になりますが、Digicomicでは漫画ページを1ページ1画像で大きく配置するルールが必要です。
`skill-creator` で作ったスキルも、作成直後に完成ではなく、実際の制作で試しながら育てます。
ここで、ひとつ具体的な場面を想像してみましょう。
モカちゃんは、AI副業の参考資料PDFを見つけました。
最初は「このPDFを全部読ませて本にして」と頼みたくなります。
しかしデジイナ先生は、「まずPDFから読者の悩みだけを抜き出しましょう」と止めます。
次に、DOCX化では「本文が完成してから組版しましょう」と順番を整えます。
最後に、同じ作業を何度もするなら `skill-creator` で自分用スキルにします。
この流れは、そのまま漫画の場面にもなります。
読者の焦りを、工程化によって落ち着かせる場面です。
この章の三つの事例は、PDFで材料を読み、DOCXで商品ファイルにし、skill-creatorで自分の制作手順を育てる流れです。
読者は最初、「公式スキルを使えば何でもできる」と思うかもしれません。
しかし、実際の気づきは、「公式スキルは完成品ではなく、信頼できる参考部品」です。
実践ステップは、公式から学び、小さく試し、自分の作業ルールに合わせて調整することです。




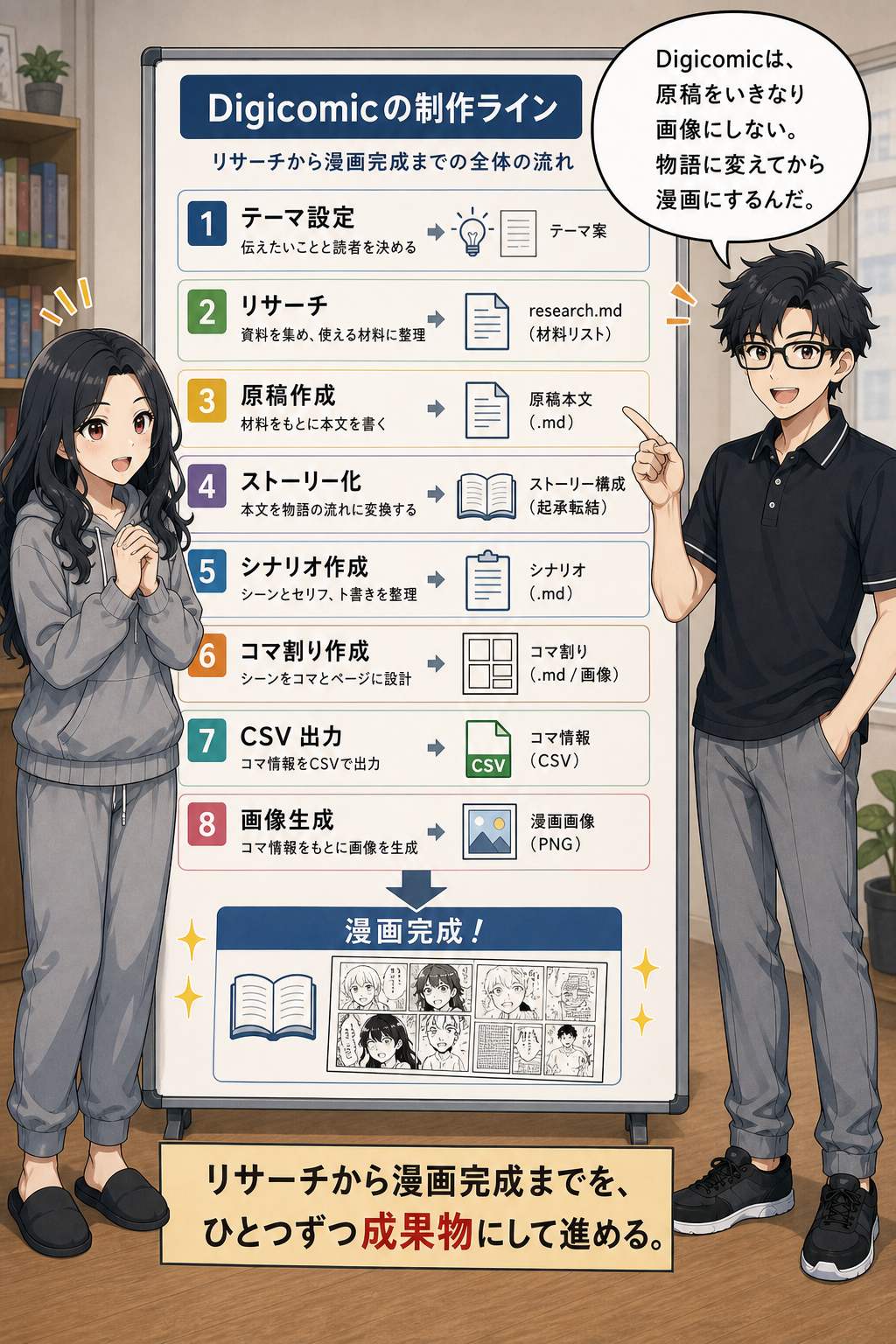
第6章: デジコミック(Digicomic)スキルの紹介
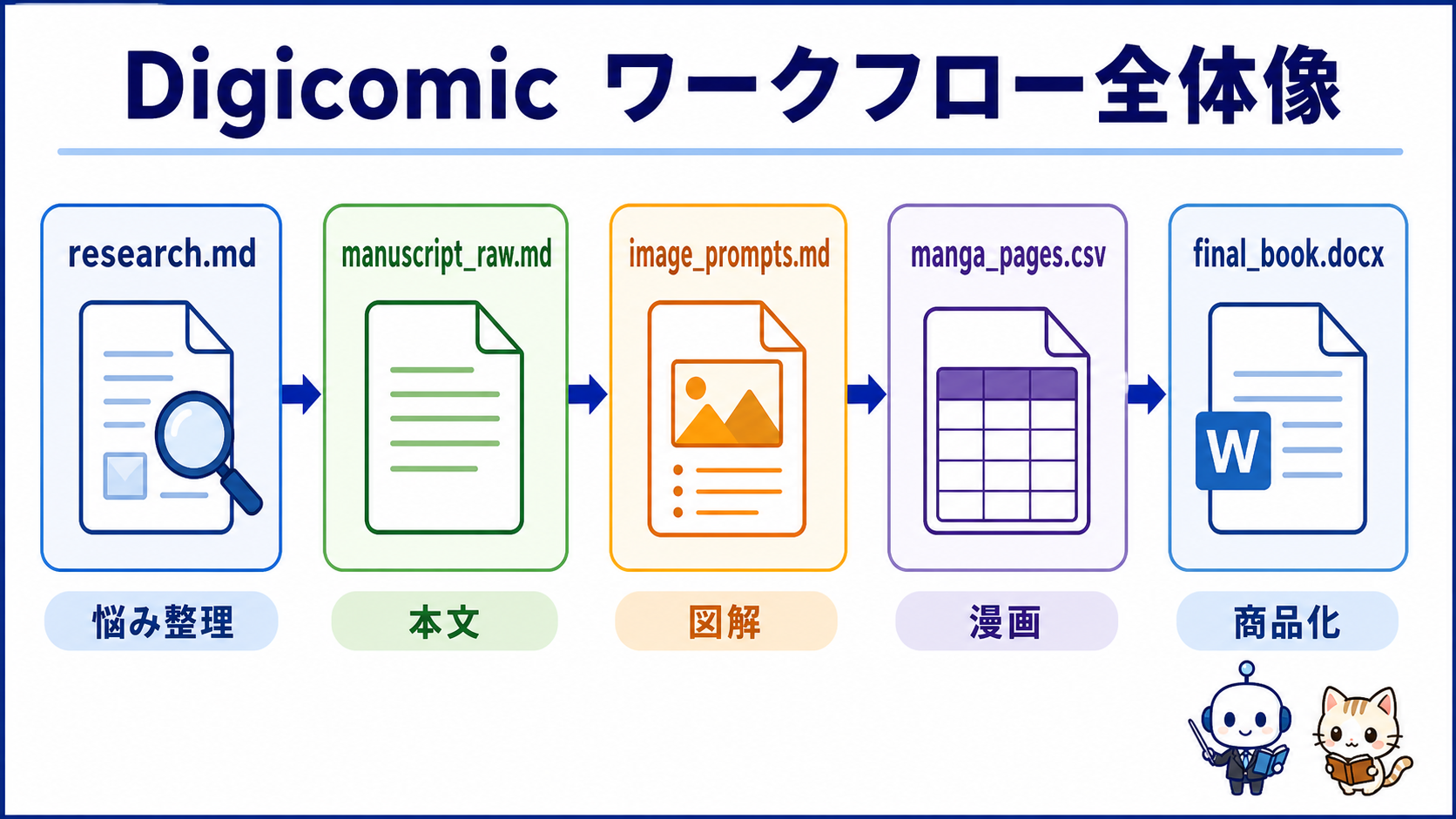
Digicomic ワークフロー全体像
Digicomicスキルは、電子書籍と漫画を一つの制作パイプラインとして扱うための仕組みです。
普通の電子書籍制作では、原稿を書いて終わりになりがちです。
しかし、初心者向けのAI副業本では、文章だけでは伝わりにくい場面があります。
読者の不安、作業の流れ、失敗からの気づき、実践ステップは、漫画や図解にすると理解しやすくなります。
Digicomicの目的は、文章、図解、漫画、DOCXを別々に作ることではありません。
リサーチから最終DOCXまでを、ひとつながりの工程として進めることです。
読者の悩みをリサーチで拾い、原稿で順番に説明し、図解で工程を見せ、漫画で感情の変化を伝え、DOCXで商品としてまとめます。
このフォルダには、工程ごとのスキルがあります。
`ebook-research` はリサーチ担当です。
テーマ、想定読者、参考資料から、読者課題、競合、構成素材、企画意図を整理し、`research.md` と `meta.json` を作ります。
ここで読者の悩みが浅いと、後の原稿も漫画も弱くなります。
だから最初に、「誰が何に困っているのか」を丁寧に書きます。
`ebook-manuscript` は原稿担当です。
`research.md` と `meta.json` を読み、`manuscript_raw.md` を作ります。
ここには章立て、本文、図解タグが入ります。
今回のように後で漫画化する場合、本文の中に読者の悩み、気づき、実践ステップが自然に流れていることが大切です。
章末に「漫画化しやすい要点」と露骨に書くのではなく、本文そのものが場面化しやすい構造になっている必要があります。
`ebook-image-gen` は図解担当です。
`manuscript_raw.md` の `HEADER_IMAGE` と `INLINE_IMAGE` タグを読み、`image_prompts.md` を作ります。
ここで重要なのは、画像を雰囲気イラストにしないことです。
図解は、読者が工程を理解するためのものです。
文字を大きく、主要ラベルを3〜5個に絞り、拡大しなくても読めるようにします。
必要に応じてデジイナ先生やモカちゃんをワンポイントで入れますが、主役はあくまで情報です。
`ebook-docx` は統合担当です。
`manuscript.md`、`images/`、`panels/` を読み、`final_book.docx` を作ります。
DOCX化は地味ですが、商品化に直結します。
読者がKindleで読む形にするには、見出し、画像、余白、ページの流れを整える必要があります。
原稿と画像ができても、DOCX化で崩れると販売できません。
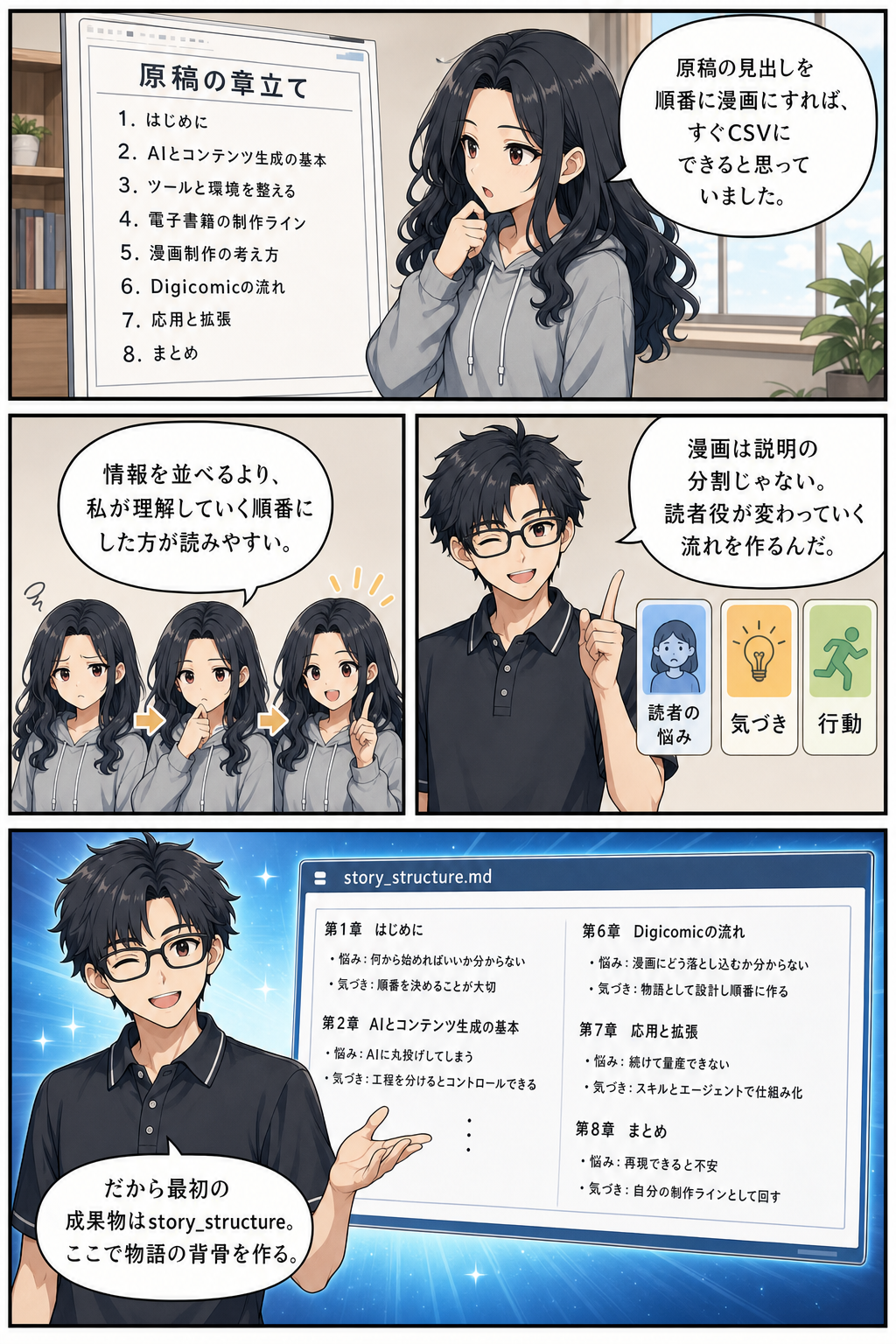
`ebook-manga` は漫画担当です。
`manuscript.md` を読み、`story_structure.md`、`manga_scenario.md`、`panel_templates.md`、`manga_pages.csv` を作ります。
ここで本文が効いてきます。
読者が「AI副業が怖い」と悩む場面、デジイナ先生が「工程を分けましょう」と気づきを渡す場面、モカちゃんが「まず作業フォルダを作ってみます」と実践する場面。
このような変化が本文にあれば、漫画化しやすくなります。
`ebook-manga-auto-ss` は司令塔です。
テーマ入力から、リサーチ、原稿、図解、漫画、DOCXまでをつなぎます。
実際の制作では、すべてを一度に自動で流すより、各工程で確認しながら進めるほうが安全です。
特に画像生成と漫画生成は、出力を見て修正する必要があります。
司令塔スキルは全体の地図であり、各工程の品質確認は人間と担当エージェントが行います。

6つのDigicomicスキル
Digicomicワークフローを、読者の変化に沿って見てみましょう。
最初の読者は、「AIでKindle本を作りたいけれど、何から始めればよいか分からない」という状態です。
`ebook-research` がこの悩みを拾い、読者像、検索意図、競合、章ごとの材料を整理します。
この時点で読者は、「自分だけが迷っているわけではない。
多くの初心者が同じところで止まる」と気づきます。
次に `ebook-manuscript` が、悩みを読みやすい順番に並べます。
ここで読者は、「AIツールの比較より先に、作業フォルダと成果物名を決めればよい」と理解します。
抽象論から具体例へ進むことで、怖さが小さくなります。
原稿の中では、ツール名を紹介するだけでなく、実際に何を作るのかを示します。
`research.md`、`manuscript_raw.md`、`image_prompts.md`、`manga_pages.csv`、`final_book.docx` という成果物名が出てくると、読者は作業をイメージできます。
次に `ebook-image-gen` が、本文の理解ポイントを図解に変えます。
たとえば「チャットAIから制作チームへ」「安全な制作フォルダ」「プロンプトとスキルの違い」「Digicomicワークフロー全体像」などです。
図解は、読者が本文に戻って理解を深めるための道しるべになります。
初心者は長文だけだと疲れるので、章ごとに図解があると安心して読み進められます。
次に `ebook-manga` が、本文を物語にします。
漫画化で大切なのは、説明をそのまま吹き出しに詰め込まないことです。
漫画は、読者の感情の変化を見せるために使います。
モカちゃんが「AIで本を作るって、どこから始めるの?」と困る。
デジイナ先生が「まず成果物名を決めましょう」と導く。
モカちゃんが `output/{slug}/` を作り、`research.md` ができて安心する。
このように、悩み、気づき、行動が場面になります。
漫画の成果物は `manga_pages.csv` です。
このCSVには、ページ番号、使用するコマ割りテンプレ、漫画作成のプロンプトが入ります。
プロンプトには、コマ番号と位置、各コマの情景、話者、ふきだし内に書く本文、参照画像とテンプレ画像を使うこと、余計な文字を描かないことを書きます。
日本漫画の読み順では、横並び2コマは右がコマ1、左がコマ2です。
コマ間に矢印は描きません。
ふきだし内には話者名を入れず、本文だけを書きます。
最後に `ebook-docx` が、本文、図解、漫画ページを統合して `final_book.docx` にします。
この時点で読者は、最初の「AIで何か作れそうだけど怖い」という状態から、「工程ごとに確認すれば、自分にも一冊を作れる」という状態に変わっています。
この変化こそ、Digicomicワークフローが読者に渡す価値です。
具体的な制作手順をもう少し細かく見ます。
Phase 1はリサーチです。
テーマ、想定読者、参考資料、強調したいポイントを入力し、`output/{slug}/research.md` と `meta.json` を作ります。
`meta.json` にはタイトル、読者、キャラ参照ディレクトリ、コマ割りテンプレディレクトリ、画像キュー用ディレクトリを入れます。
これは後工程の住所録のようなものです。
Phase 2は原稿です。
`research.md` の論点をもとに、章立てと本文を作ります。
図解タグはこの時点で入れます。
画像そのものはまだ作りません。
タグには、図解の目的、構図、入れる日本語テキスト、主要ラベル数、文字を大きくする指定、キャラクターを使う場合の指定を書きます。
後工程が迷わないタグにすることが大切です。
Phase 3は図解プロンプトです。
`ebook-image-gen` がタグを抽出し、`image_prompts.md` を作ります。
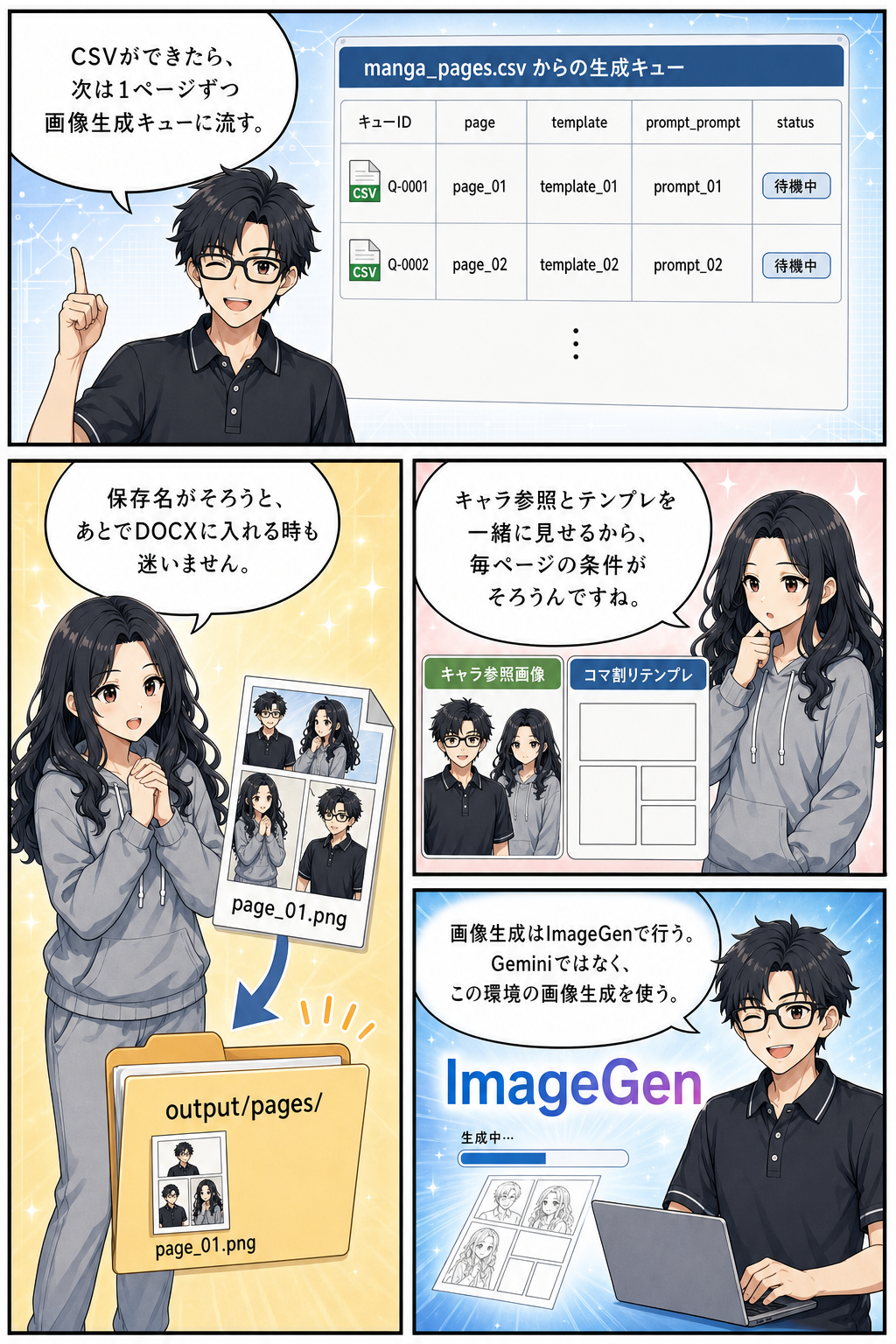
Phase 4は画像生成です。
`scripts/chat_image_queue.py status illustrations output/{slug}` で進捗を確認し、`next` で表示されるプロンプトを使って `image_gen` を呼びます。
生成画像は表示された保存先へ置き、最後に `import illustrations` で取り込みます。
Phase 5は中間DOCXです。
漫画化前に、本文と図解だけで一度DOCX化すると、文章の長さや画像位置の問題を見つけやすくなります。
Phase 6は漫画シナリオとCSVです。
`ebook-manga` が本文を読み、漫画ページに変換します。
Phase 7は漫画画像生成です。
`status manga` と `next manga` でキューを進め、参照キャラクター画像とコマ割りテンプレを添付して生成します。
Phase 8は最終DOCXです。
本文、図解、漫画を統合し、`final_book.docx` を完成させます。
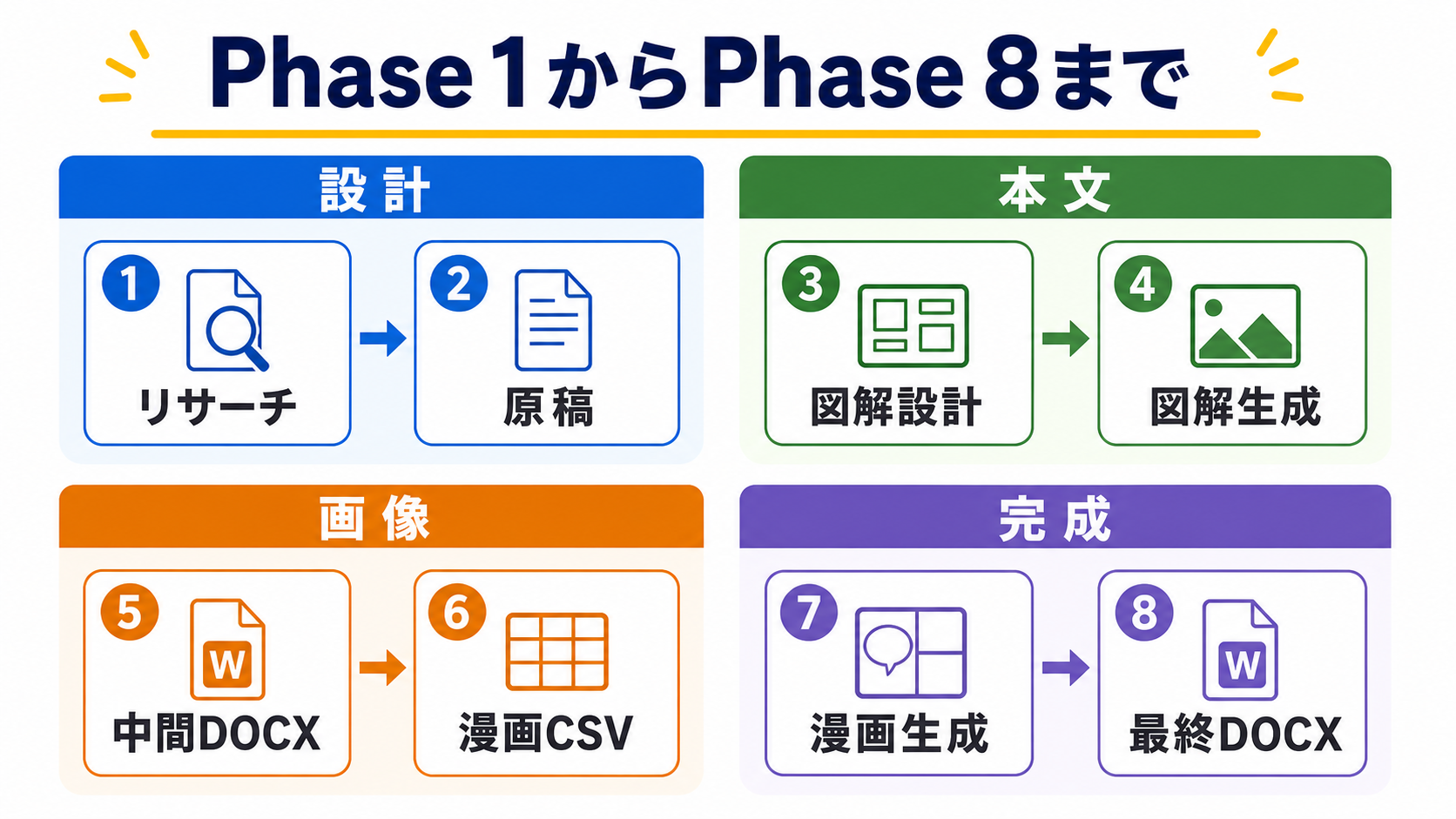
Phase 1からPhase 8まで
このワークフローの良さは、読者にそのまま見せられることです。
副業初心者は、完成品だけを見ても再現できません。
しかし、工程名と成果物名が見えれば、自分でも真似できます。
漫画化する場合も、工程が明確ならストーリーになります。
モカちゃんがPhase 1で悩みを整理し、Phase 2で原稿の形を見て、Phase 3で図解の意味を理解し、Phase 6で自分の悩みが漫画になるのを見て驚く。
読者の変化が自然に描けます。
Digicomicスキルは、作る人にもメリットがあります。
テーマを変えても、工程は変わりません。
AI副業の本でも、時間管理の本でも、英語学習の本でも、リサーチ、原稿、図解、漫画、DOCXという流れは使えます。
違うのは、読者の悩みと具体例です。
だからスキルを整えるほど、次の本が作りやすくなります。
もちろん、注意点もあります。
漫画ページは画像生成の結果に左右されます。
キャラクター参照画像がある場合は、外見を言語化せず「添付画像と完全一致」と指定します。
ふきだし文字は短くします。
1ページに説明を詰め込みすぎません。
図解も同じです。
文字が小さい図解は、Kindleでは読みにくくなります。
情報を削る勇気が必要です。
Digicomicの本質は、AIで大量に作ることではありません。
読者が理解しやすい形に変換することです。
リサーチは悩みを見つける工程。
原稿は順番を作る工程。
図解は構造を見せる工程。
漫画は感情の変化を伝える工程。
DOCXは商品にする工程。
この意味を忘れなければ、スキルは単なる自動化ではなく、読者体験を設計する道具になります。
漫画化しやすい原稿にするためには、本文の中に小さな場面が必要です。
たとえば「初心者がAI副業に興味を持つ」「情報が多すぎて止まる」「成果物名で工程を分けると安心する」「最初の `research.md` ができて前に進める」という流れです。
これは解説でありながら、漫画ではそのまま4コマの展開になります。
1コマ目は悩み、2コマ目は整理、3コマ目は実践、4コマ目は変化です。
そのため、Digicomic用の原稿では、専門用語を出す前に読者の状況を書きます。
いきなり「MCP(外部ツールへの接続口)」「Hooks(特定のタイミングで処理を動かす仕組み)」「Subagents(別の専門担当として動くAI)」と並べるのではなく、「毎回同じ確認を忘れる」「資料が散らばる」「画像生成の指示がぶれる」という悩みから入ります。
そのあとで、スキル、エージェント、キュー、CSVを紹介します。
読者の感情に沿って用語を出すと、漫画担当もキャラクターの表情やセリフを作りやすくなります。
品質チェックも工程に入れておきましょう。
原稿では、章見出しが必須構成に沿っているか、図解タグが図解専用になっているか、公式情報が古くなりそうな箇所に注意書きがあるかを見ます。
図解では、文字が大きいか、主要ラベルが多すぎないかを見ます。
漫画では、読み順、ふきだし本文、キャラクター参照、余計な文字の有無を確認します。
DOCXでは、画像抜け、空白ページ、文字化け、ページの流れを見ます。
チェック項目があることで、後工程のエージェントは安心して作業できます。
読者の悩みは、「AIで電子書籍と漫画を作るなんて難しそう」です。
気づきは、「一気に作るのではなく、工程と成果物に分ければよい」です。
実践ステップは、まず1テーマでPhase 1からPhase 2まで進めることです。
リサーチと原稿ができたら、図解タグを見直し、漫画化しやすい悩みと気づきが本文に入っているか確認します。
そこまで整えば、後工程の `ebook-image-gen` と `ebook-manga` が動きやすくなります。

おわりに
最初の一冊から制作資産へ
ここまで、Claude CodeとCodexデスクトップアプリを使い、コンテンツ制作を工程化する考え方を見てきました。
最初にお伝えしたように、コンテンツ無限生成とは、AIに丸投げして完成品が勝手に増えるという意味ではありません。
読者の悩みを起点に、リサーチ、原稿、図解、漫画、DOCX、販売素材へと展開できる仕組みを持つことです。
初心者にとって一番大きな変化は、「何を頼めばよいか分からない」状態から、「次に作る成果物が分かる」状態へ移ることです。
`research.md` ができたら、次は `manuscript_raw.md`。
図解タグが入ったら、次は `image_prompts.md`。
本文と図解が整ったら、次は漫画シナリオと `manga_pages.csv`。
最後に `final_book.docx`。
この道筋が見えるだけで、AI制作はずっと現実的になります。
Claude Codeは、作業をプロジェクトとして扱う考え方を教えてくれます。
Codexデスクトップアプリは、その作業を実際に見ながら進める場になります。
スキルは、繰り返す手順を保存するレシピです。
エージェントは、役割を持って動く作業者です。
Digicomicスキルは、それらを電子書籍と漫画の制作に合わせてまとめた実践パイプラインです。
これから始める人におすすめしたいのは、まず一冊を小さく通すことです。
完璧なテーマでなくても構いません。
まずは出力フォルダを作り、リサーチを作り、原稿を作る。
図解タグを入れる。
必要なら漫画化する。
DOCXにまとめる。
その中で必ず、つまずきが見つかります。
そのつまずきをスキルに戻してください。
これが、あなた専用の制作資産になります。
本書で紹介したDigicomicスキルは、リサーチから漫画完成までの流れをまとめるための土台です。
今後、デジコミックスキルを試してみたい方に向けて、公式LINEで配布や案内を行う予定です。
準備ができ次第、こちらに案内を入れてください。
[公式LINEのURLをここに入れる]
焦る必要はありません。
AI副業で大切なのは、派手な一発ではなく、作り続けられる仕組みです。
今日作った `manuscript_raw.md` は、ただの原稿ファイルではありません。
次の図解、次の漫画、次のDOCX、次の一冊へつながる中間成果物です。
あなたが工程を整えるほど、AIは頼れる制作チームになります。
最初の一冊は、少し時間がかかります。
それで大丈夫です。
二冊目では、使えるスキルが残っています。
三冊目では、失敗の反省がルールになっています。
四冊目では、読者の悩みから漫画化までの流れが見えてきます。
そうして少しずつ、あなたのコンテンツ制作は「毎回の根性」から「育つ仕組み」へ変わっていきます。
本書が、その最初の一歩になればうれしいです。


参考にした主な公式情報
Claude Code公式ドキュメント: https://code.claude.com/docs/
Anthropic公式 skills リポジトリ: https://github.com/anthropics/skills
OpenAI Codex公式ドキュメント: https://developers.openai.com/codex/
OpenAI Codex GitHub: https://github.com/openai/codex